Embedding-Server lokal betreiben: sentence-transformers und FastEmbed mit Qdrant
Qdrant läuft, aber was erzeugt die Vektoren? Diese Anleitung zeigt FastEmbed (direkt im qdrant-client, ONNX, keine GPU-Pflicht) und den Infinity Embedding Server (Docker, OpenAI-API) – DSGVO-konform auf eigener Hardware.
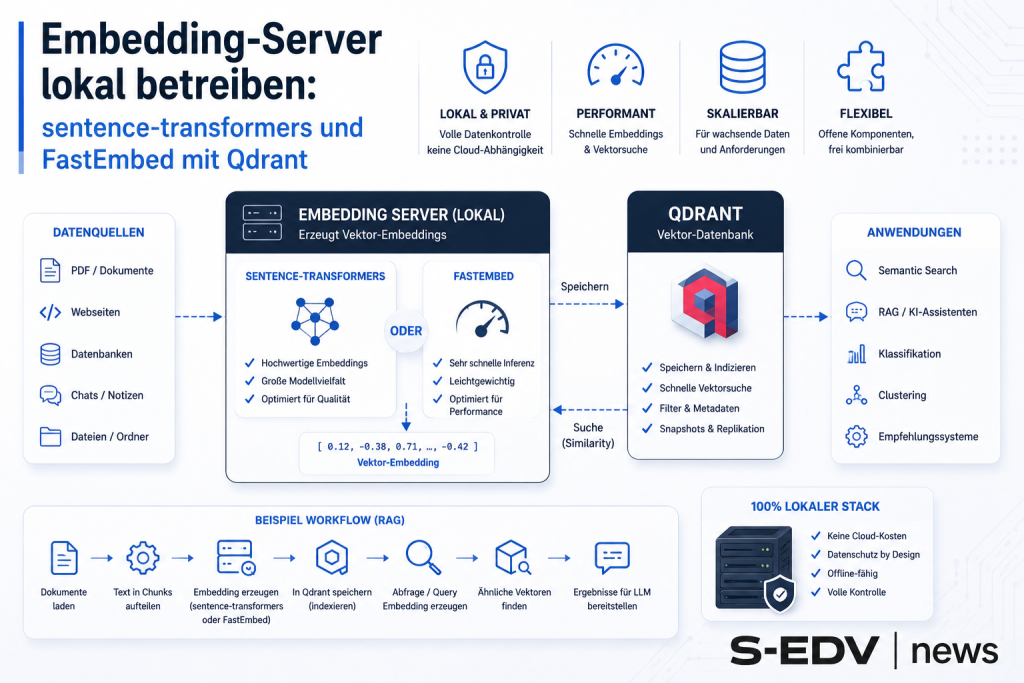
Wer einen RAG-Stack auf eigener Hardware betreibt, stößt früher oder später auf dieselbe Lücke: Qdrant läuft, die Dokumente liegen bereit – aber was wandelt die Texte eigentlich in Vektoren um? Die Antwort ist ein Embedding-Dienst, und genau dieser Baustein fehlt in vielen Anleitungen. Dieser Artikel zeigt zwei komplementäre Wege: FastEmbed als leichtgewichtige, direkt in den qdrant-client integrierte Lösung für Entwicklung und kleinere Setups sowie den Infinity Embedding Server als eigenständigen HTTP-Dienst mit OpenAI-kompatibler API für den produktiven Mehrbenutzer-Betrieb. Beide laufen on-premises in Docker, beide unterstützen sentence-transformers-Modelle von HuggingFace – und beide brauchen keine Cloud-API.
Voraussetzungen
- Server oder PC mit mindestens 4 GB RAM (8 GB empfohlen für größere Modelle)
- Docker und Docker Compose installiert (Compose-Plugin v2)
- Laufende Qdrant-Instanz (lokal oder per Docker) – siehe Lokales RAG-System mit Qdrant selbst bauen
- Python 3.9 oder neuer für direkte FastEmbed-Nutzung
- Internetverbindung für den erstmaligen Modell-Download von HuggingFace
- Optional: NVIDIA-GPU mit aktuellen CUDA-Treibern und nvidia-container-toolkit für GPU-Beschleunigung
Schritt 1: Den richtigen Weg wählen – FastEmbed oder Infinity
Bevor du loslegst, lohnt sich eine kurze Entscheidung. FastEmbed eignet sich hervorragend für Python-Skripte, Einzelanwendungen und Entwicklungsumgebungen. Infinity ist die bessere Wahl, wenn mehrere Dienste (RAGFlow, LangChain, eigene Microservices) auf denselben Embedding-Endpunkt zugreifen sollen oder wenn du eine klare Trennung zwischen Embedding-Dienst und Anwendungslogik willst.
| Kriterium | FastEmbed (qdrant-client) | Infinity Embedding Server |
|---|---|---|
| Deployment | Python-Paket, kein Dienst | Docker-Container |
| API | Python-SDK direkt | HTTP REST, OpenAI-kompatibel |
| GPU-Pflicht | Nein (ONNX CPU) | Nein (CPU-Image verfügbar) |
| Mehrere Clients | Nein | Ja |
| Dynamisches Batching | Nein | Ja |
| RAGFlow-Integration | Indirekt | Direkt (OpenAI-Schema) |
| Lizenz | Apache 2.0 | MIT |
Schritt 2: Modell wählen
Die Modellwahl entscheidet über Qualität, RAM-Bedarf und Vektordimension. Einmal festgelegt, muss die Entscheidung konsequent durchgehalten werden – alle Dokumente in einer Qdrant-Collection müssen mit demselben Modell eingebettet sein.
| Modell | Typ | Dimensionen | Größe | Sprache | Lizenz |
|---|---|---|---|---|---|
| BAAI/bge-small-en-v1.5 | Dense | 384 | 67 MB | Englisch | MIT |
| BAAI/bge-base-en-v1.5 | Dense | 768 | 210 MB | Englisch | MIT |
| BAAI/bge-large-en-v1.5 | Dense | 1024 | 1,2 GB | Englisch | MIT |
| intfloat/multilingual-e5-large | Dense | 1024 | 2,24 GB | Mehrsprachig | MIT |
| snowflake/snowflake-arctic-embed-xs | Dense | 384 | 90 MB | Englisch | Apache 2.0 |
| Qdrant/bm25 | Sparse | variabel | 10 MB | Mehrsprachig | Apache 2.0 |
| BAAI/bge-reranker-base | Reranking | – | 1,04 GB | Englisch | MIT |
Für deutschen Text empfiehlt sich intfloat/multilingual-e5-large (1024 Dimensionen, MIT-Lizenz). Für den Einstieg auf schwacher Hardware reicht BAAI/bge-small-en-v1.5 mit nur 67 MB.
Schritt 3: Weg A – FastEmbed direkt im qdrant-client
FastEmbed (Apache 2.0, v0.8.0, Stand März 2026) ist direkt in den Qdrant-Client integriert. Die ONNX-Runtime-Basis macht es schneller im Start und leichter im Speicherbedarf als eine rohe PyTorch-Installation. Eine Installation genügt:
pip install "qdrant-client[fastembed]"Das folgende Beispiel zeigt, wie du Dokumente automatisch einbettest und in Qdrant speicherst. client.add() erstellt die Collection automatisch, falls sie noch nicht existiert:
from qdrant_client import QdrantClient
client = QdrantClient("http://localhost:6333")
docs = [
"Qdrant ist eine Vektordatenbank für Semantiksuche.",
"FastEmbed nutzt ONNX Runtime für schnelle Inferenz.",
]
metadata = [
{"quelle": "intern", "typ": "erklaerung"},
{"quelle": "intern", "typ": "erklaerung"},
]
client.add(
collection_name="meine_dokumente",
documents=docs,
metadata=metadata,
)
# Semantische Suche
ergebnisse = client.query(
collection_name="meine_dokumente",
query_text="Vektordatenbank Suche",
limit=3,
)
for r in ergebnisse:
print(r.document, r.score)Verifizieren: Das Skript läuft ohne Fehler durch. In der Qdrant-Web-UI unter http://localhost:6333/dashboard erscheint die Collection „meine_dokumente" mit den eingetragenen Punkten.
Schritt 4: Weg B – Infinity Embedding Server per Docker
Der Infinity Embedding Server (MIT-Lizenz, michaelf34/infinity) ist ein eigenständiger HTTP-Dienst auf Port 7997 mit OpenAI-kompatibler REST-API. Er eignet sich für den produktiven Einsatz, wenn mehrere Anwendungen denselben Embedding-Endpunkt nutzen sollen. Vier Docker-Images decken unterschiedliche Hardware ab:
| Image-Tag | Hardware | Engine | Empfehlung |
|---|---|---|---|
| michaelf34/infinity:latest-cpu | CPU (kein GPU) | ONNX/Optimum | NAS, VM, Datenschutz-Setup |
| michaelf34/infinity:latest | NVIDIA CUDA | Torch + FlashAttention | Workstation mit NVIDIA-GPU |
| michaelf34/infinity:latest-rocm | AMD ROCm | ROCm | AMD-GPU-Server |
| michaelf34/infinity:latest-trt-onnx | NVIDIA TensorRT | TensorRT + ONNX | NVIDIA für höchsten Durchsatz |
Erstelle eine docker-compose.yml im Projektverzeichnis:
version: "3.9"
services:
embedding:
image: michaelf34/infinity:latest-cpu
# image: michaelf34/infinity:latest # GPU-Variante (nvidia-container-toolkit erforderlich)
container_name: infinity-embedding
ports:
- "7997:7997"
volumes:
- ./infinity_cache:/app/.cache
environment:
INFINITY_MODEL_ID: "BAAI/bge-base-en-v1.5"
INFINITY_PORT: "7997"
INFINITY_BATCH_SIZE: "8"
INFINITY_ANONYMOUS_USAGE_STATS: "0"
restart: unless-stoppedContainer starten und prüfen:
docker compose up -d
# Logs verfolgen (Modell wird beim ersten Start heruntergeladen)
docker compose logs -f embeddingVerifizieren: Die Swagger-UI unter http://localhost:7997/docs zeigt alle verfügbaren Endpunkte. Ein schneller API-Test:
curl -X POST http://localhost:7997/v1/embeddings \
-H "Content-Type: application/json" \
-d '{"model":"BAAI/bge-base-en-v1.5","input":["Hallo Welt","Test Embedding"]}'Die Antwort enthält ein JSON-Objekt mit "data"-Array, das pro Eingabe ein "embedding"-Feld mit 768 Floats enthält.
Schritt 5: Mehrere Modelle gleichzeitig laden
Infinity unterstützt dynamisches Batching und mehrere Modelle innerhalb einer Instanz. Das ist praktisch, wenn du Dense-Embeddings für die Hauptsuche und ein Sparse-Modell für Keyword-Fallback parallel betreiben willst:
docker run -it \
-v $PWD/infinity_cache:/app/.cache \
-p 7997:7997 \
michaelf34/infinity:latest-cpu \
v2 \
--model-id BAAI/bge-base-en-v1.5 \
--model-id intfloat/multilingual-e5-large \
--port 7997Beachte: Jedes geladene Modell belegt separaten RAM. Zwei mittlere Modelle gleichzeitig binden schnell 3–5 GB – Kapazität vor dem Start prüfen.
Schritt 6: Infinity-API in Qdrant nutzen (Python)
Das folgende vollständige Beispiel zeigt, wie du über den Infinity-HTTP-Endpunkt Embeddings holst, eine Qdrant-Collection anlegst und Dokumente einpflegst:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
import requests
def embed(texts: list[str], model="BAAI/bge-base-en-v1.5") -> list[list[float]]:
resp = requests.post(
"http://localhost:7997/v1/embeddings",
json={"model": model, "input": texts},
)
resp.raise_for_status()
return [d["embedding"] for d in resp.json()["data"]]
client = QdrantClient("http://localhost:6333")
# Collection anlegen (768 Dimensionen für bge-base-en-v1.5)
client.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(size=768, distance=Distance.COSINE),
)
# Dokumente einpflegen
texts = ["Erster Satz", "Zweiter Satz"]
vektoren = embed(texts)
client.upsert(
collection_name="docs",
points=[
PointStruct(id=i, vector=v, payload={"text": t})
for i, (t, v) in enumerate(zip(texts, vektoren))
],
)
# Suche
query_vec = embed(["Semantische Suche"])[0]
treffer = client.search(collection_name="docs", query_vector=query_vec, limit=3)
for t in treffer:
print(t.score, t.payload["text"])Schritt 7: GPU-Betrieb einrichten (optional)
Wer eine NVIDIA-GPU hat und auf dem Host das nvidia-container-toolkit installiert hat, wechselt einfach das Image und ergänzt --gpus all:
# Voraussetzung: nvidia-container-toolkit auf dem Host
docker run -it --gpus all \
-v $PWD/infinity_cache:/app/.cache \
-p 7997:7997 \
michaelf34/infinity:latest \
v2 \
--model-id BAAI/bge-large-en-v1.5 \
--port 7997Ohne nvidia-container-toolkit startet das latest-Image mit einem CUDA-Fehler. In diesem Fall das latest-cpu-Image verwenden – es läuft auf reiner CPU mit ONNX-Engine und ist für die meisten KMU-Workloads ausreichend. Die CUDA-Einrichtung ist in der Anleitung CUDA-Umgebung korrekt aufsetzen beschrieben.
Troubleshooting / Typische Fehler
Vektordimension stimmt nicht
Wenn du eine Collection mit 768 Dimensionen angelegt hast und dann das Modell auf eines mit 384 Dimensionen wechselst, schlägt der Upsert mit einem Dimension-Mismatch-Fehler fehl. Lösung: Die Collection löschen (client.delete_collection("docs")) und mit der neuen Dimension neu anlegen. Alle Dokumente müssen danach neu eingelesen werden.
GPU-Container startet nicht
Fehlermeldung wie CUDA error: no kernel image is available for execution on the device oder Container-Exit ohne Log. Ursache: Das latest-Image setzt nvidia-container-toolkit voraus. Entweder das Toolkit installieren oder auf latest-cpu wechseln.
Modell wird bei jedem Neustart neu heruntergeladen
Ohne Volume-Mount lädt Infinity das Modell bei jedem Containerstart neu von HuggingFace. Bei bge-large (1,2 GB) kostet das mehrere Minuten. Abhilfe: Den -v $PWD/infinity_cache:/app/.cache-Mount immer mitangeben.
RAM-Engpass bei großen Modellen
intfloat/multilingual-e5-large (2,24 GB Download) benötigt im Betrieb deutlich mehr RAM als die Downloadgröße vermuten lässt. Mindestens 4 GB freien RAM pro geladenem Großmodell einplanen. Bei mehreren Modellen entsprechend mehr.
Telemetrie aktiv
Infinity sendet standardmäßig anonyme Nutzungsstatistiken. Für datenschutzkonforme Deployments die Umgebungsvariable INFINITY_ANONYMOUS_USAGE_STATS=0 explizit setzen – ist im obigen Compose-Beispiel bereits enthalten.
FastEmbed unterstützt das Wunschmodell nicht
FastEmbed unterstützt nur Modelle aus seiner eigenen Model-Liste (ONNX-optimiert). Eigene oder sehr neue HuggingFace-Modelle erfordern einen manuellen ONNX-Export. Infinity hingegen unterstützt alle sentence-transformers-Modelle von HuggingFace direkt.
Häufige Fragen
Muss ich einen separaten Embedding-Server betreiben oder genügt FastEmbed?
Für Entwicklung und kleine Workloads genügt qdrant-client[fastembed] vollständig – kein separater Dienst nötig. Für Produktion, mehrere Dienste oder wenn RAGFlow separat embedden soll, empfiehlt sich Infinity als eigenständiger HTTP-Dienst.
Welches Modell soll ich für deutschen Text wählen?
intfloat/multilingual-e5-large (1024 Dimensionen, MIT-Lizenz) ist die bewährte Wahl für mehrsprachige Inhalte inklusive Deutsch. Für kleinere Deployments mit weniger RAM: intfloat/multilingual-e5-small (384 Dimensionen, ca. 117 MB).
Wie integriere ich Infinity als Embedding-Quelle in RAGFlow?
RAGFlow kann externe Embedding-Endpunkte nutzen. Da Infinity dem OpenAI-Schema folgt (/v1/embeddings), lässt sich RAGFlow mit dem Infinity-Endpunkt (http://infinity:7997) als „OpenAI-kompatibler Anbieter" konfigurieren – vorausgesetzt, beide Container sind im selben Docker-Netzwerk. Die RAGFlow-Einrichtung selbst ist in RAGFlow mit Docker installieren beschrieben.
Läuft das auch auf einem NAS ohne GPU?
Ja. Das latest-cpu-Image mit ONNX-Engine läuft auf reiner CPU. BAAI/bge-small-en-v1.5 (67 MB) ist für schwache Hardware geeignet. Auf einem modernen NAS mit x86-CPU sind ca. 50–200 ms pro Anfrage realistisch.
Was ist der Unterschied zwischen Dense-, Sparse- und Late-Interaction-Vektoren?
Dense (z. B. bge-base): Ein Vektor pro Dokument, gut für semantische Ähnlichkeit. Sparse (SPLADE): Viele Nullen, gut für Keyword-nahe Suche. Late Interaction (ColBERT): Mehrere Vektoren pro Dokument, höhere Qualität aber mehr Speicher. Qdrant unterstützt alle drei; für einfache RAG-Anwendungen genügen Dense-Vektoren. Mehr dazu in RAG produktiv betreiben: Chunking, Hybrid-Search und Reranking.
Kann ich FastEmbed und Infinity gleichzeitig nutzen?
Ja – und das kann sinnvoll sein: FastEmbed direkt im Python-Code für schnelle Abfragen, Infinity als HTTP-Dienst für andere Anwendungen. Wichtig: Beide müssen dasselbe Modell verwenden, wenn sie auf dieselbe Qdrant-Collection schreiben.
Fazit
Ein lokaler Embedding-Dienst ist kein optionales Extra, sondern der fehlende Baustein jedes datenschutzkonformen RAG-Stacks. FastEmbed macht den Einstieg denkbar einfach: Ein pip-Befehl, und der qdrant-client erledigt Einbettung und Datenbankzugriff in einem Schritt. Für den produktiven Mehrbenutzer-Betrieb oder die Integration mit RAGFlow und anderen Diensten liefert der Infinity Embedding Server eine saubere, OpenAI-kompatible HTTP-Schnittstelle – mit dynamischem Batching und GPU-Option bei Bedarf. Beide Wege laufen vollständig on-premises, ohne Cloud-Abhängigkeit und ohne Datenschutzrisiko. Die wichtigste Faustregel: Modell einmal wählen, konsequent durchhalten – und das Volume für den Modell-Cache nicht vergessen.
Weiterführende Anleitungen und Quellen
- Lokales RAG-System mit Qdrant und Embeddings selbst bauen
- RAGFlow mit Docker installieren
- RAG produktiv betreiben: Chunking, Hybrid-Search, Reranking und Antwortqualität messen
- CUDA-Umgebung korrekt aufsetzen: Treiber, Toolkit, cuDNN und PyTorch
- FastEmbed – offizielles GitHub-Repository (qdrant/fastembed)
- Infinity Embedding Server – GitHub (michaelf34/infinity)
- FastEmbed – unterstützte Modelle (offizielle Dokumentation)
- Qdrant Embeddings – Integrationsübersicht