Lokales RAG-System mit Qdrant und Embeddings selbst bauen: Schritt-für-Schritt-Anleitung
So richtest du ein Qdrant RAG System lokal ein: Qdrant via Docker, BGE-M3 Embeddings, Chunking deiner PDF/TXT-Dokumente und Abfrage per Ollama-LLM - mit Fokus auf deutsche Texte.
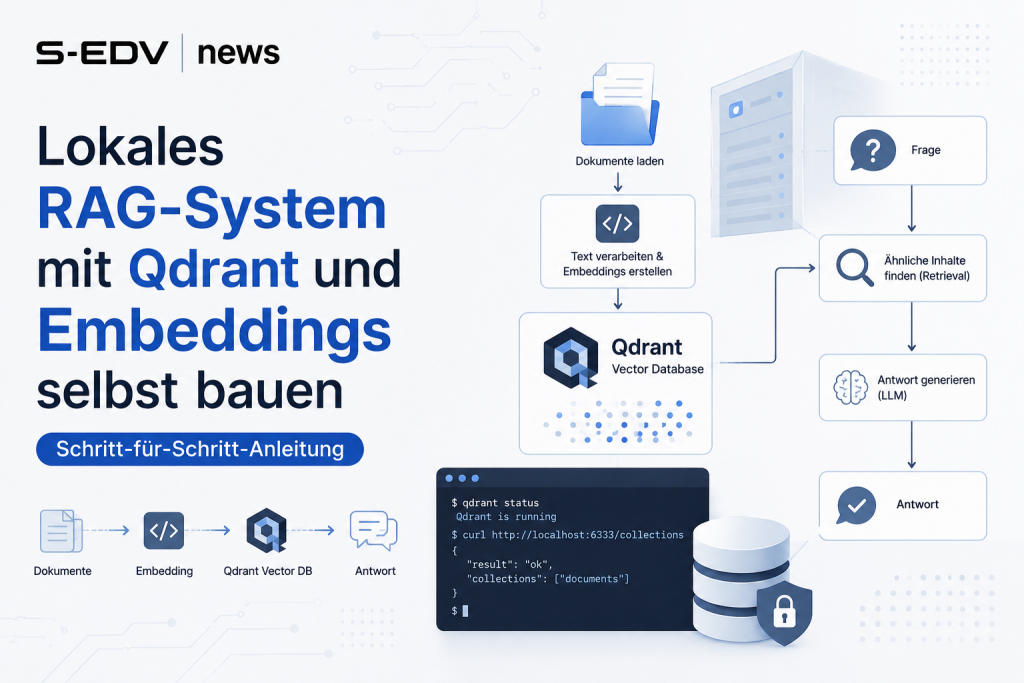
Wenn du ein Qdrant RAG System lokal einrichten willst, brauchst du keine Cloud und keinen API-Schlüssel. In dieser Anleitung baust du einen kompletten Retrieval-Augmented-Generation-Stack auf deinem eigenen Server oder Homeserver: Qdrant als Vektordatenbank in Docker, das mehrsprachige Embedding-Modell BGE-M3 zur Vektorisierung deiner Texte, LangChain als Klebstoff und Ollama als lokales LLM-Backend. Am Ende kannst du deine eigenen PDF- und TXT-Dokumente hochladen, sie in Vektoren umwandeln, in der Datenbank speichern und in natürlicher Sprache abfragen - vollständig offline und mit besonderem Fokus auf deutsche Dokumente. Diese Anleitung richtet sich an Admins, Selfhoster und Entwickler, die ein datenschutzfreundliches Frage-Antwort-System über ihre eigenen Unterlagen aufbauen wollen.
Was ist RAG und warum mit Qdrant lokal?
Retrieval-Augmented Generation (RAG) verbindet ein Sprachmodell mit einer durchsuchbaren Wissensbasis. Statt sich nur auf das Trainingswissen des LLM zu verlassen, sucht das System zur Laufzeit die thematisch passenden Textabschnitte aus deinen eigenen Dokumenten heraus (Retrieval) und gibt sie dem Modell als Kontext mit (Generation). So beantwortet das LLM Fragen anhand deiner aktuellen Daten - mit deutlich weniger Halluzinationen und nachvollziehbaren Quellen.
Damit die Suche funktioniert, werden Texte in Embeddings umgewandelt: numerische Vektoren, die die Bedeutung eines Abschnitts abbilden. Ähnliche Inhalte liegen im Vektorraum nahe beieinander. Genau diese Vektoren speichert und durchsucht eine Vektordatenbank. Qdrant ist eine in Rust geschriebene, quelloffene Vektordatenbank, die als Docker-Container in Sekunden läuft, sehr schnelle Nearest-Neighbor-Suche bietet und sich über eine HTTP- und gRPC-API ansprechen lässt. Lokal betrieben bleiben deine Dokumente auf deiner Hardware - ideal für sensible interne Unterlagen.
Für deutsche Texte ist die Modellauswahl entscheidend. BGE-M3 ist multilingual, deckt über 100 Sprachen inklusive Deutsch ab und steht unter der MIT-Lizenz. Eine gleichwertige Alternative ist multilingual-e5-large. Beide erzeugen deutlich bessere Treffer für deutschsprachige Dokumente als rein englische Modelle.
Voraussetzungen
- Ein Linux-Server, Homeserver oder Windows-Rechner mit Docker und Docker Compose (siehe unsere Anleitung zur Docker-Installation).
- Python 3.9 oder neuer sowie
pip. - Mindestens 8 GB RAM; für komfortables Arbeiten mit größeren LLMs sind 16 GB empfehlenswert. Eine GPU beschleunigt Embeddings und LLM, ist aber nicht zwingend.
- Rund 5-10 GB freier Speicher für Container-Images, das Embedding-Modell und ein LLM.
- Ollama als lokales LLM-Backend. Wenn du Ollama noch nicht betreibst, hilft dir unsere Anleitung Ollama mit Open WebUI in Docker als lokales LLM beim Aufsetzen.
- Deine Quelldokumente als PDF- oder TXT-Dateien in einem Ordner.
Schritt 1: Qdrant als Docker-Container starten
Qdrant lässt sich mit einem einzigen Befehl starten. Für einen schnellen Test reicht:
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrantPort 6333 ist die HTTP-/REST-API (und das Web-Dashboard), Port 6334 die gRPC-Schnittstelle. Für den Dauerbetrieb solltest du die Daten persistent ablegen, damit sie einen Container-Neustart überleben. Lege dazu eine docker-compose.yml an:
services:
qdrant:
image: qdrant/qdrant
container_name: qdrant
restart: unless-stopped
ports:
- "6333:6333"
- "6334:6334"
volumes:
- ./qdrant_storage:/qdrant/storageStarte den Stack im Hintergrund:
docker compose up -dÖffne anschließend im Browser das Dashboard unter http://localhost:6333/dashboard. Dort siehst du später deine Collections und kannst Vektoren inspizieren.
Schritt 2: Python-Umgebung und Bibliotheken vorbereiten
Lege ein Projektverzeichnis an und erstelle eine virtuelle Umgebung, damit die Abhängigkeiten sauber gekapselt bleiben:
mkdir rag-projekt && cd rag-projekt
python3 -m venv .venv
source .venv/bin/activateUnter Windows aktivierst du die Umgebung stattdessen mit:
python -m venv .venv
.\.venv\Scripts\Activate.ps1Installiere nun die benötigten Pakete. Wir nutzen die offizielle LangChain-Integration langchain-qdrant, dazu langchain-community für Loader und Embeddings sowie sentence-transformers für BGE-M3:
pip install langchain langchain-community langchain-qdrant \
qdrant-client sentence-transformers pypdf langchain-ollamaSchritt 3: Dokumente laden und in Chunks zerlegen
Lange Dokumente müssen vor der Vektorisierung in kleinere, überlappende Abschnitte (Chunks) zerlegt werden. Zu große Chunks verwässern die Suche, zu kleine reißen Zusammenhänge auseinander. Für deutsche Fließtexte sind etwa 1000 Zeichen pro Chunk mit 150 Zeichen Überlappung ein guter Startwert. Lege eine Datei ingest.py an:
from langchain_community.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import glob, os
docs = []
for pfad in glob.glob("dokumente/**/*", recursive=True):
if pfad.lower().endswith(".pdf"):
docs.extend(PyPDFLoader(pfad).load())
elif pfad.lower().endswith(".txt"):
docs.extend(TextLoader(pfad, encoding="utf-8").load())
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=150,
separators=["\n\n", "\n", ". ", " ", ""],
)
chunks = splitter.split_documents(docs)
print(f"{len(docs)} Dokumente -> {len(chunks)} Chunks")Lege deine PDF- und TXT-Dateien in einen Unterordner dokumente/. Achte beim TextLoader auf encoding="utf-8", sonst können Umlaute in deutschen Texten verstümmelt werden.
Schritt 4: Embeddings mit BGE-M3 erzeugen
Jetzt wird BGE-M3 als Embedding-Modell eingebunden. Beim ersten Lauf lädt sentence-transformers das Modell automatisch von Hugging Face herunter und cached es lokal. Ergänze ingest.py:
from langchain_community.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-m3",
model_kwargs={"device": "cpu"}, # "cuda" bei vorhandener GPU
encode_kwargs={"normalize_embeddings": True},
)Die Option normalize_embeddings=True normiert die Vektoren, was zur Kosinus-Distanz in Qdrant passt. Möchtest du stattdessen multilingual-e5-large verwenden, ersetze den model_name durch intfloat/multilingual-e5-large. BGE-M3 erzeugt Vektoren mit 1024 Dimensionen. Diese Vektorgröße musst du nicht manuell angeben - LangChain ermittelt sie beim Anlegen der Collection automatisch.
Schritt 5: Vektoren in Qdrant speichern
Mit QdrantVectorStore schreibst du die Chunks samt Embeddings direkt in eine Collection. LangChain legt die Collection bei Bedarf automatisch mit der richtigen Vektorgröße und Kosinus-Distanz an. Vervollständige ingest.py:
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
vectorstore = QdrantVectorStore.from_documents(
documents=chunks,
embedding=embeddings,
url="http://localhost:6333",
collection_name="meine_dokumente",
)
print("Indexierung abgeschlossen.")Führe das Skript aus:
python ingest.pyJe nach Dokumentmenge und Hardware dauert dieser Schritt einige Sekunden bis Minuten. Im Qdrant-Dashboard taucht danach die Collection meine_dokumente mit der Anzahl deiner Chunks auf.
Schritt 6: Abfrage per LLM über Ollama
Nun verbindest du Retrieval und Generation. Lade zunächst ein Modell in Ollama, etwa ein kompaktes deutschtaugliches Modell:
ollama pull llama3.1Erstelle eine Datei query.py, die die passenden Chunks aus Qdrant holt und an das LLM übergibt:
from langchain_qdrant import QdrantVectorStore
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_ollama import ChatOllama
from langchain.chains import RetrievalQA
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-m3",
encode_kwargs={"normalize_embeddings": True},
)
vectorstore = QdrantVectorStore.from_existing_collection(
embedding=embeddings,
url="http://localhost:6333",
collection_name="meine_dokumente",
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
llm = ChatOllama(model="llama3.1", temperature=0)
qa = RetrievalQA.from_chain_type(
llm=llm, retriever=retriever, return_source_documents=True
)
antwort = qa.invoke({"query": "Worum geht es in meinen Dokumenten?"})
print(antwort["result"])
for doc in antwort["source_documents"]:
print("Quelle:", doc.metadata.get("source"))Mit k=4 holt der Retriever die vier ähnlichsten Chunks. Über return_source_documents=True bekommst du die Herkunft der Antwort angezeigt - wichtig für die Nachvollziehbarkeit.
Schritt 7: Verifikation und erster Test
Prüfe zuerst, ob Qdrant erreichbar ist und die Collection korrekt angelegt wurde:
curl http://localhost:6333/collections/meine_dokumenteDie JSON-Antwort sollte den Status green und die Anzahl der gespeicherten Punkte (points_count) enthalten. Stelle dann eine konkrete Frage zu einem Detail, das nur in deinen Dokumenten steht:
python query.pyWenn die Antwort inhaltlich zu deinen Unterlagen passt und plausible Quellen nennt, funktioniert die gesamte Kette aus Chunking, BGE-M3-Embeddings, Qdrant-Retrieval und Ollama-Generation. Bekommst du generische oder falsche Antworten, prüfe in Schritt 8 die Chunk-Größe und den k-Wert.
Schritt 8: Updates und Wartung
Halte die Komponenten regelmäßig aktuell. Das Qdrant-Image aktualisierst du so:
docker compose pull
docker compose up -dNeue oder geänderte Python-Pakete spielst du mit pip install -U langchain langchain-qdrant qdrant-client ein. Wenn du Dokumente hinzufügst, kannst du ingest.py erneut ausführen - neue Chunks werden ergänzt. Bei stark geänderten Beständen ist es sauberer, die Collection vorher zu löschen und neu aufzubauen, damit keine veralteten Vektoren zurückbleiben.
Backup nicht vergessen
Alle Vektoren und Metadaten liegen im gemounteten Verzeichnis ./qdrant_storage. Sichere dieses Verzeichnis regelmäßig, am besten bei gestopptem Container, um einen konsistenten Zustand zu erhalten:
docker compose stop qdrant
tar czf qdrant-backup-$(date +%F).tar.gz qdrant_storage
docker compose start qdrantAlternativ bietet Qdrant über die API Snapshots an, die sich ebenfalls extern wegsichern lassen. Die Quelldokumente selbst solltest du ohnehin separat in deinem normalen Backup führen, denn aus ihnen lässt sich der Index jederzeit neu erzeugen.
Troubleshooting
- Connection refused auf Port 6333: Der Qdrant-Container läuft nicht. Prüfe mit
docker compose psund sieh dir die Logs mitdocker compose logs qdrantan. - Verstümmelte Umlaute: TXT-Dateien wurden mit falschem Encoding geladen. Setze
encoding="utf-8"im TextLoader und prüfe die Quelldatei. - Modell-Download bricht ab: BGE-M3 ist mehrere Hundert MB groß. Stelle stabile Internetverbindung und genug Plattenplatz sicher; der Cache liegt unter
~/.cache/huggingface. - Antworten ignorieren die Dokumente: Erhöhe den
k-Wert (z. B. auf 6-8) oder verkleinere die Chunk-Größe. Prüfe, obpoints_countwirklich Daten enthält. - Out of Memory: Wähle ein kleineres Ollama-Modell oder verarbeite die Dokumente in Schritt 3 batchweise statt alle auf einmal.
- Dimensionsfehler beim Indexieren: Du hast das Embedding-Modell gewechselt, aber die alte Collection behalten. Lösche die Collection und indexiere neu.
Häufige Fragen
Welches Embedding-Modell ist für deutsche Texte am besten?
Für RAG mit deutschen Dokumenten sind multilinguale Modelle Pflicht. BGE-M3 (MIT-Lizenz) liefert sehr gute Ergebnisse über mehr als 100 Sprachen hinweg, eine ebenbürtige Alternative ist multilingual-e5-large. Rein englische Modelle wie das ältere all-MiniLM liefern für deutsche Texte deutlich schlechtere Treffer.
Brauche ich für ein lokales RAG-System eine GPU?
Nein. Sowohl die Embeddings mit BGE-M3 als auch das LLM über Ollama laufen auf der CPU. Eine GPU beschleunigt die Vektorisierung großer Dokumentmengen und die Antwortgenerierung jedoch erheblich. Setze dazu device="cuda" bei den Embeddings und nutze ein GPU-fähiges Ollama-Setup.
Wie viele Dokumente kann Qdrant lokal verwalten?
Qdrant skaliert problemlos auf Millionen von Vektoren auf einem einzelnen Server, sofern genug RAM und Speicher vorhanden sind. Für typische Homeserver-Szenarien mit einigen tausend bis hunderttausend Chunks reicht handelsübliche Hardware völlig aus.
Kann ich statt Ollama ein anderes LLM-Backend nutzen?
Ja. Für höheren Durchsatz oder mehrere parallele Anfragen eignet sich vLLM als Backend. Da LangChain die LLM-Schicht abstrahiert, tauschst du lediglich die Modell-Klasse aus, während Chunking, Embeddings und Qdrant unverändert bleiben.
Werden meine Daten an einen externen Dienst gesendet?
Nein, sofern alle Komponenten lokal laufen. Qdrant, BGE-M3 und Ollama arbeiten vollständig offline auf deiner Hardware. Lediglich der einmalige Download des Embedding-Modells und des LLM erfordert eine Internetverbindung.
Fazit
Mit Qdrant, BGE-M3, LangChain und Ollama hast du ein vollständig lokales RAG-System aufgebaut, das deine eigenen PDF- und TXT-Dokumente versteht und in natürlicher Sprache beantwortet - ohne Cloud, ohne API-Kosten und mit voller Datenhoheit. Der Stack ist modular: Du kannst das Embedding-Modell, das LLM oder die Chunking-Strategie jederzeit anpassen, ohne den Rest umzubauen. Für deutsche Dokumente sind die Wahl eines multilingualen Embedding-Modells und das korrekte UTF-8-Encoding die wichtigsten Stellschrauben für gute Trefferqualität.
Weiterführende Anleitungen und Quellen
Wenn du Docker noch einrichten musst, starte mit unserer Docker-Installationsanleitung. Das passende LLM-Backend baust du mit der Anleitung Ollama mit Open WebUI in Docker als lokales LLM auf. Wer die RAG-Pipeline später an ein leistungsfähiges, gehostetes Modell anbinden möchte, findet im Beitrag zum Release von Anthropic Claude Opus 4.8 Hintergründe zur aktuellen Modellgeneration. Weitere Container-Projekte findest du in unserer Kategorie Docker.
Quellen: Offizielle Qdrant-Dokumentation (qdrant.tech/documentation), LangChain-Qdrant-Integration (python.langchain.com) und das BGE-M3-Modell auf Hugging Face (huggingface.co/BAAI/bge-m3).


