Ollama und Open WebUI mit Docker: eigenes lokales KI-Sprachmodell ohne Cloud betreiben
Mit Ollama und Open WebUI betreibst du per Docker Compose ein eigenes KI-Sprachmodell komplett lokal: ein ChatGPT-ähnliches Web-Interface, das ohne Cloud läuft und deine Daten im Haus behält. Diese Anleitung zeigt das Setup Schritt für Schritt - mit Modell-Download, GPU-Option und Wartung.
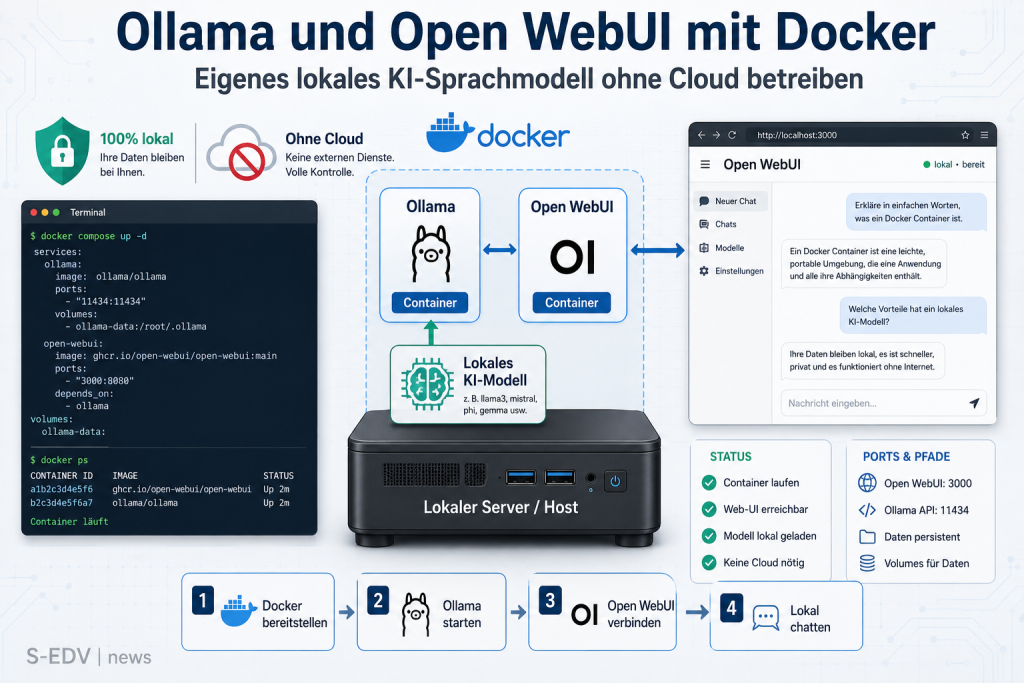
Du möchtest ein eigenes KI-Sprachmodell betreiben, ohne deine Eingaben an OpenAI, Google oder Anthropic zu schicken? Mit Ollama als Modell-Server und Open WebUI als Chat-Oberfläche baust du dir per Docker Compose in wenigen Minuten ein lokales ChatGPT-Pendant. Alle Daten bleiben auf deiner eigenen Hardware, die Verarbeitung läuft komplett offline. Diese Anleitung richtet sich an Homeserver-Bastler und Admins, die einen Debian/Ubuntu-Host mit Docker betreiben und lokale Large Language Models (LLMs) wie Llama 3.2, Gemma 2 oder Qwen 2.5 nutzen wollen.
Was sind Ollama und Open WebUI?
Ollama ist ein schlanker Server, der LLMs lädt, verwaltet und über eine HTTP-API bereitstellt. Du lädst Modelle mit einem einzigen Befehl (ollama pull llama3.2) und sprichst sie dann über die API auf Port 11434 an. Ollama übernimmt das Quantisieren, das Laden in den Arbeitsspeicher und - wenn vorhanden - die GPU-Beschleunigung.
Open WebUI ist ein Web-Frontend, das sich mit Ollama verbindet und eine komfortable Chat-Oberfläche im Browser bietet: Konversationsverlauf, mehrere Modelle parallel, Benutzerverwaltung und Datei-Uploads inklusive. Die Oberfläche erinnert bewusst an bekannte Cloud-Chats, läuft aber vollständig bei dir.
Der große Vorteil: Datenschutz. Nichts verlässt dein Netzwerk, du brauchst keinen API-Schlüssel und keine Internetverbindung (außer einmalig zum Modell-Download). Das ist ideal für vertrauliche Texte, Code oder einfach zum Experimentieren ohne laufende Kosten.
Voraussetzungen
- Ein Linux-Host (Debian 12 oder Ubuntu 22.04/24.04 empfohlen) mit installiertem Docker und Docker Compose Plugin
- RAM ist der wichtigste Faktor: mindestens 8 GB für kleine 3B-Modelle, 16 GB für komfortables Arbeiten mit 7B/8B-Modellen
- Ausreichend Plattenplatz: Modelle belegen je nach Größe 2-9 GB, mehrere Modelle entsprechend mehr
- Freie Host-Ports
8080(Open WebUI) und optional11434(Ollama-API) - Optional für Beschleunigung: eine NVIDIA-GPU mit installiertem
nvidia-container-toolkit - Einen Webbrowser für den ersten Login
Prüfe zuerst, ob Docker korrekt installiert ist:
docker --version
docker compose versionFalls Docker fehlt, installierst du es am schnellsten mit dem offiziellen Skript und nimmst deinen Benutzer in die Gruppe docker auf:
curl -fsSL https://get.docker.com | sudo sh
sudo usermod -aG docker $USERDanach einmal ab- und wieder anmelden, damit die Gruppenzugehörigkeit greift.
Schritt 1: Projektordner und Volumes anlegen
Lege einen Ordner für den Stack an. Wir nutzen hier /opt/ollama, du kannst aber auch ein Verzeichnis in deinem Home-Ordner verwenden.
sudo mkdir -p /opt/ollama
cd /opt/ollamaDie eigentlichen Daten - heruntergeladene Modelle und die Open-WebUI-Datenbank - landen in benannten Docker-Volumes, die wir gleich in der Compose-Datei definieren. So bleiben sie auch bei einem Neuaufsetzen der Container erhalten.
Schritt 2: docker-compose.yml erstellen
Erstelle im Projektordner eine Datei docker-compose.yml mit folgendem Inhalt. Dieser Stack startet beide Container und verbindet sie über ein internes Netzwerk - Open WebUI erreicht Ollama unter dem Hostnamen ollama.
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
volumes:
- ollama-data:/root/.ollama
# Port nur freigeben, wenn du die API direkt nutzen willst:
# ports:
# - "11434:11434"
open-webui:
image: ghcr.io/open-webui/open-webui:latest
container_name: open-webui
restart: unless-stopped
depends_on:
- ollama
ports:
- "8080:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
volumes:
- open-webui:/app/backend/data
volumes:
ollama-data:
open-webui:Wichtig ist die Zeile OLLAMA_BASE_URL=http://ollama:11434: Sie sagt Open WebUI, wo der Modell-Server erreichbar ist. Da beide Container im selben Compose-Netzwerk laufen, genügt der Service-Name ollama als Hostname. Den Port 11434 musst du nur dann nach außen freigeben (auskommentierter ports-Block), wenn andere Tools direkt mit der Ollama-API sprechen sollen.
Schritt 3: Stack starten
Starte beide Container im Hintergrund:
docker compose up -dBeim ersten Start werden die Images ollama/ollama und ghcr.io/open-webui/open-webui heruntergeladen - das kann je nach Verbindung ein paar Minuten dauern. Prüfe danach den Status:
docker compose psBeide Container sollten als running erscheinen. Die Logs siehst du bei Bedarf mit docker compose logs -f.
Schritt 4: Erstes Modell herunterladen
Ollama startet zunächst ohne Modelle. Du lädst ein Modell entweder später bequem über die Open-WebUI-Oberfläche oder direkt per Kommandozeile im Container. Für den Einstieg eignet sich das kleine, schnelle llama3.2 (3B):
docker exec -it ollama ollama pull llama3.2Weitere bewährte Modelle, je nach verfügbarem RAM:
ollama pull gemma2- Googles Gemma 2, gute Allround-Qualitätollama pull qwen2.5- stark bei Code und mehrsprachigollama pull llama3.2:1b- winziges 1B-Modell für schwache Hardware
Welche Modelle bereits lokal liegen, zeigt dir:
docker exec -it ollama ollama listFaustregel zum Speicher: Ein 7B/8B-Modell in Standard-Quantisierung belegt rund 5-6 GB RAM, ein 3B-Modell etwa 2-3 GB. Reicht der Arbeitsspeicher nicht, antwortet das Modell entweder sehr langsam oder der Container wird vom System beendet. Im CPU-only-Betrieb sind 3B- bis 7B-Modelle realistisch, größere Modelle brauchen eine GPU.
Schritt 5: Open WebUI öffnen und Admin-Konto anlegen
Rufe im Browser http://SERVER-IP:8080 auf (ersetze SERVER-IP durch die Adresse deines Hosts, lokal also http://localhost:8080). Beim ersten Aufruf legst du ein Konto an.
- Klicke auf Konto erstellen bzw. Sign up.
- Gib Name, E-Mail und ein Passwort ein.
- Der erste registrierte Benutzer wird automatisch zum Administrator - merke dir diese Zugangsdaten gut.
Diese E-Mail und das Passwort sind nur lokal, du kannst also eine beliebige Adresse wie admin@local verwenden. Achte trotzdem auf ein starkes Passwort, falls die Oberfläche später erreichbar gemacht wird.
Nach dem Login wählst du oben im Chat das gewünschte Modell (z. B. llama3.2) aus und stellst deine erste Frage. Modelle lassen sich übrigens auch direkt in der WebUI nachladen: unter Einstellungen → Modelle einfach einen Modellnamen wie gemma2 eintragen und herunterladen.
Schritt 6 (optional): GPU-Beschleunigung mit NVIDIA aktivieren
Hast du eine NVIDIA-GPU, beschleunigt sie die Antworten erheblich. Installiere zunächst das nvidia-container-toolkit nach der offiziellen NVIDIA-Anleitung und starte den Docker-Dienst neu. Ergänze danach den ollama-Service in der Compose-Datei um die GPU-Reservierung:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
volumes:
- ollama-data:/root/.ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]Nach docker compose up -d nutzt Ollama nun die Grafikkarte. Ob die GPU erkannt wird, prüfst du mit:
docker exec -it ollama nvidia-smiOhne GPU funktioniert alles ebenfalls - nur eben langsamer und allein über die CPU. Für reine Textaufgaben mit kleinen Modellen ist das durchaus brauchbar.
Updates und Wartung
Beide Images werden aktiv weiterentwickelt. Ein Update ziehst du so:
cd /opt/ollama
docker compose pull
docker compose up -dAlte, ungenutzte Images entfernst du danach mit docker image prune. Deine Modelle und Chats bleiben dabei erhalten, da sie in den Volumes liegen.
Für den Produktivbetrieb empfiehlt es sich, statt :latest einen festen Tag zu pinnen, damit ein Update nicht unbemerkt etwas verändert. Prüfe dazu die jeweils aktuelle Versionsempfehlung in der offiziellen Dokumentation und trage den passenden Tag ein.
Backup
Sicherungswürdig ist vor allem das Volume open-webui - dort liegen Benutzer, Einstellungen und Chatverläufe. Die Modelle im Volume ollama-data kannst du jederzeit neu herunterladen, ein Backup ist hier optional (spart aber Zeit). Ein einfaches Archiv erstellst du z. B. so:
docker run --rm -v open-webui:/data -v $(pwd):/backup alpine \
tar czf /backup/open-webui-backup.tar.gz -C /data .Auf einem NAS nimmst du die Docker-Volumes entsprechend in deine regelmäßige Datensicherung (z. B. Hyper Backup) auf.
Troubleshooting
- Open WebUI zeigt keine Modelle: Prüfe, ob die Variable
OLLAMA_BASE_URL=http://ollama:11434korrekt gesetzt ist und beide Container im selben Netzwerk laufen. Test:docker exec -it open-webui curl http://ollama:11434sollteOllama is runningausgeben. - Container wird beim Antworten beendet (OOMKilled): Das Modell ist zu groß für den RAM. Wähle ein kleineres Modell wie
llama3.2:1boder rüste Arbeitsspeicher nach. - Antworten extrem langsam: Ohne GPU rechnet die CPU - normal bei größeren Modellen. Kleineres Modell wählen oder GPU einrichten (Schritt 6).
- Port 8080 bereits belegt: Ändere das Port-Mapping in der Compose-Datei, z. B. auf
3000:8080, und rufe die Oberfläche unter dem neuen Port auf. - GPU wird nicht genutzt:
nvidia-container-toolkitinstalliert und Docker neu gestartet? Mitdocker exec -it ollama nvidia-smiprüfen.
Hinweis für Synology-Nutzer
Grundsätzlich läuft dieser Stack auch im Container Manager unter DSM 7.2 als Projekt. Sinnvoll ist das aber nur auf Modellen mit ausreichend RAM - die meisten Synology-NAS haben für LLMs zu wenig Arbeitsspeicher und keine nutzbare GPU. Wenn dein NAS 16 GB oder mehr RAM hat, kannst du den gleichen docker-compose.yml-Inhalt im Container Manager als Projekt anlegen, die Volumes liegen dann unter /volume1/docker/ollama. Für ernsthafte Nutzung ist ein dedizierter Linux-Host die bessere Wahl.
Fazit
Mit Ollama und Open WebUI hast du in wenigen Schritten ein eigenes, vollständig lokales KI-Sprachmodell aufgesetzt - ohne Cloud, ohne API-Kosten und ohne dass deine Eingaben das eigene Netzwerk verlassen. Der Stack ist leicht zu warten, über Volumes sicher gegen Container-Neustarts und lässt sich jederzeit um weitere Modelle erweitern. Wie schnell und wie groß die Modelle laufen, hängt vor allem an deinem RAM und einer optionalen GPU. Für den Einstieg reichen kleine 3B-Modelle auf der CPU - und du behältst die volle Kontrolle über deine Daten.
Weitere Anleitungen in den Kategorien Docker und Synology / NAS.
Quellen: Ollama (GitHub), Open WebUI Dokumentation, Open WebUI (GitHub)