ZFS in der Praxis: Snapshots, Scrub, Replikation und Pool-Tuning richtig nutzen
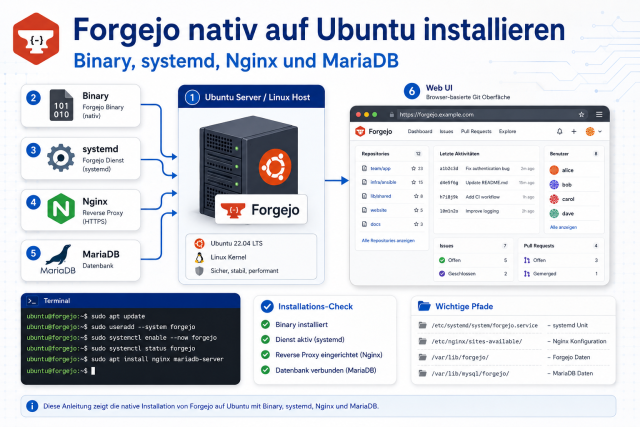
ZFS-Snapshots sind kein Backup – erst die Replikation auf einen physisch getrennten Host schützt vor Datenverlust. Diese Anleitung zeigt, wie du Snapshots, automatisierte Retention mit sanoid/syncoid, regelmäßige Scrubs und gezieltes Pool-Tuning (ashift, recordsize, LZ4, ARC) gemeinsam einsetzt.
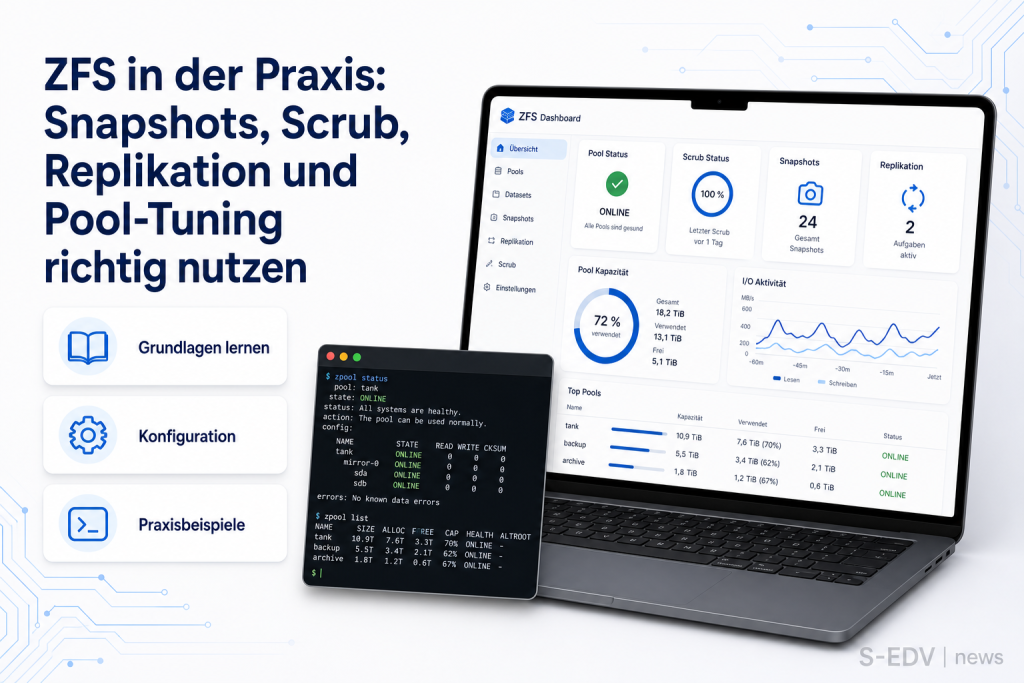
ZFS gehört zu den leistungsfähigsten Dateisystemen für Linux-Server – aber nur, wenn du seine vier Säulen konsequent einsetzt: Copy-on-Write-Snapshots für schnelle Zwischenstände, automatisierte Retention mit sanoid/syncoid für saubere Replikation auf einen anderen Host, regelmäßige Scrubs gegen Bit-Rot und gezieltes Pool-Tuning für maximale Performance. Der teuerste Irrtum in der Praxis: Snapshots im gleichen Pool als „Backup" zu betrachten. Diese Anleitung räumt damit auf und zeigt, wie alle vier Säulen zusammenspielen.
Voraussetzungen
- Linux mit OpenZFS 2.x: Ubuntu 22.04+/24.04, Debian 12+, Proxmox VE 8+ (
apt install zfsutils-linux) oder FreeBSD 14+ (nativ integriert) - Root- oder sudo-Zugang auf Produktions- und Backup-Host
- Mindestens ein konfigurierter ZFS-Pool (
zpool createabgeschlossen) - SSH-Schlüssel-Authentifizierung zwischen Quell- und Ziel-Host (kein Passwort-Prompt im Cronjob) – siehe SSH-Key-Authentifizierung einrichten
- sanoid installiert:
apt install sanoid(Ubuntu/Debian) oder aktuelles Release von GitHub - Optional:
apt install mbufferfür große Netzwerk-Replikations-Transfers - Separate physische Hardware für den Backup-Host – kein Backup-Pool im gleichen Gehäuse wie Produktion
- Faustregel RAM: mindestens 1 GB RAM pro TB genutztem Pool-Speicher für effektiven ARC-Betrieb
Schritt 1: Pool korrekt erstellen – ashift von Anfang an richtig setzen
ashift bestimmt die minimale Blockgröße je vdev und ist nach der Pool-Erstellung unveränderlich. Ein falscher Wert – z. B. ashift=9 (512 Byte) auf modernen 4K-SSDs – erzwingt Read-Modify-Write bei jedem Schreibzugriff und verursacht dauerhaften Performance-Verlust. Die einzige Abhilfe ist, den Pool zu zerstören und neu zu erstellen.
- HDDs und SSDs mit 4K-Sektoren (aktueller Standard):
ashift=12 - Manche NVMe-SSDs mit 8K-Sektoren:
ashift=13 - Immer Disk-by-ID-Pfade verwenden, damit nach einem Neustart die richtige Platte gemappt wird
# Mirror-Pool mit korrektem ashift (SSD/NVMe 4K-Sektoren)
zpool create -o ashift=12 tank mirror \
/dev/disk/by-id/ata-SSD_A \
/dev/disk/by-id/ata-SSD_B
# LZ4-Komprimierung am Root-Dataset aktivieren (alle Children erben)
zfs set compression=lz4 tankLZ4 ist der empfohlene Default: Er erreicht über 10 GB/s Durchsatz und ist damit praktisch nie der Bottleneck – aktiviere ihn generell am Pool-Root, damit alle Datasets automatisch profitieren.
Schritt 2: recordsize workload-spezifisch setzen
Der Standard-recordsize in OpenZFS ist 128 KiB. Für Datenbanken und VMs ist dieser Wert zu groß und verursacht unnötigen Write-Amplification-Overhead. Wichtig: Eine Änderung an recordsize wirkt nur auf neu geschriebene Blöcke – Bestandsdaten behalten ihre ursprüngliche Blockgröße. Für eine bestehende Datenbank ist ein Dump & Restore nötig.
| Workload | Empfohlener recordsize | Begründung |
|---|---|---|
| MySQL InnoDB | 16K | Entspricht InnoDB-Seitengröße |
| PostgreSQL | 8K oder 16K | Entspricht PostgreSQL-Blockgröße (Standard 8K) |
| QEMU/KVM (qcow2) | 64K | Typische VM-I/O-Größe |
| Sequenziell / NAS / Archiv | 1M | Maximiert sequenziellen Durchsatz |
| Datenbank-Logs | 128K (Default) | Große sequenzielle Writes |
# recordsize-Empfehlungen setzen
zfs set recordsize=16K tank/mysql-data
zfs set recordsize=128K tank/mysql-logs
zfs set recordsize=8K tank/postgres
zfs set recordsize=64K tank/vms
zfs set recordsize=1M tank/archivSchritt 3: ARC-Limit konfigurieren
Der ARC (Adaptive Replacement Cache) nutzt verfügbaren RAM automatisch und ist standardmäßig auf ~50 % des physischen RAMs begrenzt. Auf Systemen, auf denen ZFS mit anderen speicherhungrigen Diensten koexistiert, solltest du ein explizites Maximum setzen. Wichtig: L2ARC verbraucht ca. 30–100 MB RAM pro GB SSD-Cache für Metadaten – auf RAM-knappen Systemen kann ein zu großes L2ARC-Gerät den ARC schrumpfen und die Performance verschlechtern.
# ARC-Maximum auf 16 GB begrenzen
# Datei: /etc/modprobe.d/zfs.conf
options zfs zfs_arc_max=17179869184Nach einer Änderung ist ein Neustart oder echo 17179869184 > /sys/module/zfs/parameters/zfs_arc_max nötig, um den Wert sofort anzuwenden.
Schritt 4: Snapshots verstehen und manuell nutzen
Snapshots sind read-only, COW-basierte Referenzen auf den Zustand eines Datasets zum Erstellungszeitpunkt. Initial kosten sie keinen zusätzlichen Platz, wachsen aber mit jeder geänderten Block-Differenz. Das Wichtigste zuerst: Snapshots auf demselben Pool sind kein Backup. Geht der Pool verloren (Festplattenausfall jenseits RAIDZ-Kapazität, Brand, Controller-Defekt), gehen Daten und Snapshots gemeinsam verloren.
# Snapshot manuell anlegen
zfs snapshot tank/daten@backup-2026-06-04
# Snapshots mit Platzverbrauch auflisten
zfs list -t snapshot -o name,used,referenced,creation -s creation -r tank
# Platz durch Snapshots je Dataset anzeigen
zfs list -o name,used,usedbychildren,usedbysnapshots tank
# Snapshot wiederherstellen (Rollback)
zfs rollback tank/daten@backup-2026-06-04
# Snapshot löschen
zfs destroy tank/daten@backup-2026-06-04Achtung Speicherfalle: Ohne automatisches Pruning wächst der Snapshot-Platzverbrauch still bis zur 100 %-Auslastung. Symptom: zpool: no space left. Prüfe regelmäßig mit zfs list -o name,usedbysnapshots -r tank.
Schritt 5: sanoid für automatisierte Retention konfigurieren
sanoid v2.3.0 ist das Standard-Werkzeug für policy-basierte Snapshot-Retention. Es erstellt und löscht Snapshots nach konfigurierbaren Regeln und wird einmal pro Minute via Cron oder systemd-Timer aufgerufen.
# /etc/sanoid/sanoid.conf
[tank/daten]
use_template = produktion
recursive = yes
[template_produktion]
frequently = 0
hourly = 36
daily = 30
weekly = 4
monthly = 3
yearly = 0
autosnap = yes
autoprune = yes
[backup/daten]
use_template = backup_empfang
recursive = yes
[template_backup_empfang]
frequently = 0
hourly = 36
daily = 90
weekly = 4
monthly = 6
yearly = 0
autosnap = no
autoprune = yes# sanoid via Cron (UTC-Timezone empfohlen)
* * * * * TZ=UTC /usr/local/bin/sanoid --cronDas backup_empfang-Template mit autosnap = no und längerer Retention stellt sicher, dass der Backup-Host eigene, längere Aufbewahrungsfristen hat, ohne selbst neue Snapshots zu erstellen.
Schritt 6: Replikation mit syncoid einrichten
syncoid ist das Replikations-Frontend aus dem sanoid-Paket und orchestriert intern zfs send/receive. Es unterstützt Push- und Pull-Modus, SSH-Key-Auth, Komprimierung im Transit und rekursive Replikation.
Push vs. Pull: Im Push-Modus kann ein kompromittierter Produktionsserver den Backup-Server überschreiben (zfs receive -F). Im Pull-Modus holt der Backup-Server aktiv – das verhindert, dass Produktionszugriff die Sicherung korrumpiert. Pull ist die sicherere Wahl.
# Push-Replikation (stündlich, Minute 2)
02 * * * * root syncoid -r --no-sync-snap --compress=lzo --quiet \
tank/daten backup/daten
# Pull-Replikation mit SSH-Key (Backup-Server holt von Produktion)
20 * * * * root syncoid --sshkey=/root/.ssh/syncoid \
-r --no-sync-snap --compress=lzo --quiet \
syncoid@prodserver:tank/daten backup/prodserver/datenFür große Netzwerk-Transfers empfiehlt sich mbuffer, um I/O-Jitter zu glätten:
# mbuffer für große Transfers
zfs send -R -i tank/daten@v1 tank/daten@v2 \
| mbuffer -s 128k -m 1G \
| ssh backup 'zfs receive -u backup/daten'Schritt 7: zfs send/receive direkt nutzen
Wer die volle Kontrolle über Replikationsjobs benötigt oder kein sanoid einsetzt, kann zfs send/receive direkt orchestrieren. Hier sind die wichtigsten Flags:
| Flag | Bedeutung |
|---|---|
-i snap1 snap2 | Delta zwischen genau zwei Snapshots (kein Intermediate-History) |
-I snap1 snap2 | Alle Zwischen-Snapshots – erhält vollständige Snapshot-Geschichte |
-R | Repliziert kompletten Dataset-Baum inkl. Properties |
-w | Raw Encrypted Send – Empfänger braucht keine Schlüssel |
-n -v | Dry-Run: schätzt Größe ohne tatsächliche Übertragung |
# Erstsicherung (Full Send) auf Remote-Host
zfs send -R tank/daten@snap-v1 | ssh backup 'zfs receive -u -F backup/daten'
# Inkrementeller Send (exakt zwei Snapshots)
zfs send -i tank/daten@snap-v1 tank/daten@snap-v2 \
| ssh backup 'zfs receive -u backup/daten'
# Dry-Run: Größe eines inkrementellen Sends schätzen
zfs send -n -v -i tank/daten@snap-v1 tank/daten@snap-v2
# Verschlüsselter Raw-Send (Empfänger braucht keine Schlüssel)
zfs send -w tank/geheim@snap-v1 | ssh backup 'zfs receive -u backup/geheim'
# Unterbrochenen Transfer fortsetzen
TOKEN=$(ssh backup 'zfs get -H -o value receive_resume_token backup/daten')
zfs send -t ${TOKEN} | ssh backup 'zfs receive -u backup/daten'
# Bookmark anlegen (Anker ohne Snapshot-Overhead)
zfs bookmark tank/daten@snap-v2 tank/daten#repl-baseBookmarks (#name statt @name) ermöglichen es, den Replikations-Anker zu behalten, ohne den Snapshot selbst vorzuhalten – wichtig, wenn Platzbedarf auf dem Sender reduziert werden soll, ohne die Inkrementalität zu brechen.
Schritt 8: Scrubs gegen Bit-Rot planen
Scrubs lesen jeden allokierten Block und verifizieren seinen Checksum. Korrupte Blöcke werden bei vorhandener Redundanz (Mirror, RAIDZ) automatisch repariert. Scrubs immer in Wartungsfenstern planen – auf saturierten Pools erhöht ein Tages-Scrub die I/O-Latenz spürbar.
# Scrub manuell starten
zpool scrub tank
# Scrub-Status prüfen
zpool status -v tankFür automatische monatliche Scrubs nutzt du am besten einen systemd-Timer mit Persistent=true, damit verpasste Läufe nach einer Downtime nachgeholt werden. Lege dazu zwei Dateien an:
# /etc/systemd/system/zfs-scrub@.service
[Unit]
Description=ZFS Scrub auf %i
[Service]
Type=oneshot
ExecStart=/sbin/zpool scrub %i# /etc/systemd/system/zfs-scrub@.timer
[Unit]
Description=ZFS Scrub auf %i monatlich
[Timer]
OnCalendar=monthly
Persistent=true
[Install]
WantedBy=timers.target# Timer aktivieren
sudo systemctl enable --now zfs-scrub@tank.timerEmpfohlener Rhythmus: monatlich für kleine Heimnetz-Pools, alle 1–2 Wochen für große Produktions-Pools. Nach jedem Festplatten-, HBA- oder Kabelwechsel immer einen manuellen Scrub anstoßen.
Troubleshooting / Typische Fehler
- „zpool: no space left on device" – Vergessene Snapshots belegen den Pool. Prüfe mit
zfs list -o name,usedbysnapshots -r tankund lösche alte Snapshots oder aktiviereautoprune = yesin sanoid. - „cannot receive incremental stream: most recent snapshot does not match incremental source" – Der gemeinsame Replikations-Anker wurde gelöscht. Lösung: Bookmarks statt Snapshots als Anker nutzen oder autoprune-Policies auf Sender und Empfänger koordinieren, damit der Basis-Snapshot nie vor der nächsten Replikation gelöscht wird.
- CKSUM-Fehler in zpool status – SMART kann Controller- und Kabelfehler nicht erkennen, ZFS schon. CKSUM-Fehler niemals kommentarlos mit
zpool clearlöschen – zuerst Hardware (Kabel, HBA, RAM) prüfen. - Empfangs-Dataset wird automatisch gemountet – Ohne
-ubeimzfs receiveodercanmount=offauf dem Backup-Pool kann ein Indexer (mlocate, Virenschutz) in Backup-Datasets schreiben. Immerzfs receive -uverwenden. - recordsize-Änderung zeigt keine Wirkung –
zfs set recordsize=16Kwirkt nur auf neue Schreibvorgänge. Für Bestandsdaten (z. B. bestehende Datenbank) ist ein Dump & Restore nötig (pg_dump + Restore, mysqldump + Import). - Scrub erhöht Latenz tagsüber – Scrubs in Wartungsfenster (Nacht/Wochenende) verschieben; alternativ I/O-Scheduler-Limits über
zfs_scan_vdev_limitsetzen.
Häufige Fragen
Ist ein ZFS-Snapshot ein Backup?
Nein. Ein Snapshot lebt im gleichen Pool wie die Originaldaten. Fällt der Pool aus – durch Festplattenausfall jenseits der RAIDZ-Kapazität, Brand oder Controller-Defekt – gehen Daten und Snapshots gemeinsam verloren. Ein echtes Backup erfordert zfs send/receive auf einen physisch getrennten Host oder ein anderes Medium.
Wie oft sollte ich scrubben?
Als Faustregel gilt: monatlich für kleine Heimnetz-Pools, alle 1–2 Wochen für große Produktions-Pools mit langer Snapshot-Retention. Nach jedem Festplatten-, HBA- oder Kabelwechsel immer einen manuellen Scrub anstoßen. Der systemd-Timer mit Persistent=true stellt sicher, dass verpasste Läufe nach einer Downtime nachgeholt werden.
Kann ich recordsize nachträglich ändern?
Den Wert kann man jederzeit mit zfs set recordsize=X setzen, aber er wirkt nur auf neue Schreibvorgänge. Bestehende Dateien behalten ihre ursprüngliche Blockgröße. Um den neuen recordsize auf Bestandsdaten anzuwenden, müssen die Daten neu geschrieben werden – z. B. per Dump & Restore bei Datenbanken.
Warum syncoid statt direktem zfs send/receive?
sanoid/syncoid übernimmt Snapshot-Benennung, Retention-Policy, Bookmark-Management, Fehlerbehandlung und Resume-Token-Logik automatisch. Ein selbst gebautes zfs send/receive-Skript muss all das manuell implementieren und ist deutlich fehleranfälliger – besonders beim Handling von unterbrochenen Transfers und dem gemeinsamen Replikations-Anker.
Was ist der Unterschied zwischen zfs send -i und -I?
-i sendet nur die Differenz zwischen genau zwei Snapshots, ohne Zwischen-History. -I sendet alle Zwischen-Snapshots im Bereich und erhält damit die vollständige Snapshot-Geschichte auf dem Empfänger – wichtig, wenn aus einem alten Zwischenstand wiederhergestellt werden soll.
Wieviel RAM braucht der ARC wirklich?
Der ARC skaliert automatisch mit verfügbarem RAM (Standard-Maximum: ~50 %). Als grobe Richtlinie gilt: 1 GB RAM pro TB genutztem Pool-Speicher. Für Deduplizierung werden ca. 320 Bytes RAM pro einzigartigem Block benötigt – das kann schnell mehrere Dutzend GB werden, weshalb Deduplizierung nur bei ausreichend RAM sinnvoll ist.
Fazit
ZFS entfaltet sein volles Potenzial erst, wenn alle vier Säulen zusammenspielen: Snapshots für schnelle Zwischenstände, Replikation auf einen getrennten Host als echtes Off-Host-Backup, regelmäßige Scrubs gegen Bit-Rot und workload-spezifisches Tuning. Die drei dauerhaftesten Entscheidungen sind ashift (nach Pool-Erstellung unveränderlich), recordsize (wirkt nur auf neue Blöcke) und die Replikationsrichtung (Pull statt Push aus Sicherheitsgründen). Mit sanoid/syncoid und einem systemd-Timer für Scrubs läuft das Fundament dann weitgehend wartungsfrei – und du schläfst ruhiger, weil Snapshots und Backup sauber getrennt sind.
Weiterführende Anleitungen und Quellen
- Festplatten, Partitionen, LVM und fstab unter Linux
- SSH-Key-Authentifizierung einrichten (Linux & Windows)
- systemd-Services erstellen und verwalten
- Linux-Server absichern mit UFW und fail2ban
Quellen: OpenZFS Workload Tuning | Klara Systems: Tuning recordsize in OpenZFS | GitHub: jimsalterjrs/sanoid | cr0x.net: ZFS Scrub Frequency | cr0x.net: ZFS Incremental Send Backups | oxcrag.net: ZFS Backup Strategy with Sanoid and Syncoid | cr0x.net: ZFS ashift Mismatch Detection