rsync über SSH: Daten synchronisieren und migrieren
rsync über SSH sicher nutzen: Quelle und Ziel prüfen, Dry-Run ausführen, Rechte verstehen und Daten kontrolliert synchronisieren.
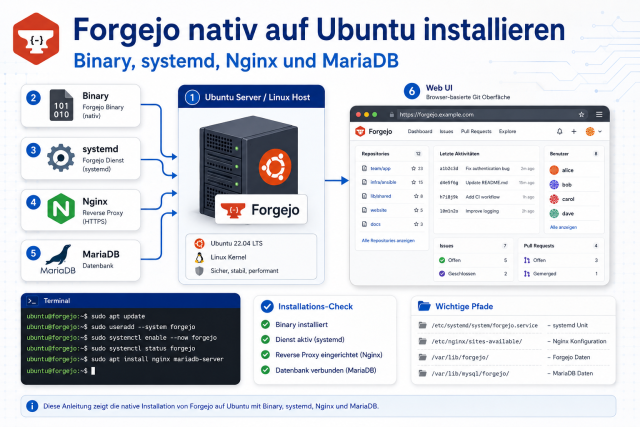
rsync über SSH ist einer der nützlichsten Linux-Bausteine für Backups, Datenumzüge und wiederholbare Synchronisierung. Die Stärke von rsync liegt nicht nur in der Übertragung selbst, sondern darin, dass du Änderungen effizient nachziehen, das Ergebnis erneut prüfen und Befehle mit wenig Aufwand wiederholen kannst.
Voraussetzungen
- Zwei erreichbare Systeme oder ein lokales und ein entferntes Ziel
- SSH-Zugang
- Ausreichende Rechte auf Quelle und Ziel
Schritt 1: Quelle, Ziel und Slash-Bedeutung verstehen
Bei rsync entscheidet oft ein einzelner Slash über das Ergebnis. /quelle/ bedeutet meist „Inhalt des Ordners“, /quelle eher „Ordner selbst“.
Verifizieren: Du gehst erst weiter, wenn dir klar ist, welcher Ordnerinhalt und welches Ziel wirklich betroffen sein soll.
Schritt 2: Verbindung per SSH testen
ssh user@zielserverWenn du Schlüssel nutzt, passt dazu unsere Anleitung SSH-Key-Authentifizierung einrichten.
Verifizieren: Der Schritt ist erfolgreich, wenn du das Zielsystem sauber erreichst.
Schritt 3: Ersten Dry-Run mit rsync ausführen
rsync -avh --dry-run /quelle/ user@zielserver:/ziel/Der Dry-Run zeigt dir, was passieren würde, ohne Daten wirklich zu übertragen oder zu löschen.
Verifizieren: Prüfe die geplante Datei- und Ordnerliste genau. Erst wenn Quelle und Ziel logisch aussehen, darf die echte Synchronisierung starten.
Schritt 4: Echte Synchronisierung starten
rsync -avh /quelle/ user@zielserver:/ziel/Die Option -a ist für viele Admin-Fälle die wichtigste Grundlage, weil sie rekursiv arbeitet und viele Attribute erhält.
Verifizieren: Der Schritt ist erfolgreich, wenn die Übertragung ohne Fehler endet und das Ziel die erwarteten Dateien enthält.
Schritt 5: Rechte, Besitzer und Löschverhalten bewusst einsetzen
rsync kann mehr als nur kopieren. Genau deshalb solltest du Erweiterungen wie --delete bewusst verwenden.
rsync -avh --delete /quelle/ user@zielserver:/ziel/Wichtig: --delete löscht auf dem Ziel Dateien, die in der Quelle nicht mehr vorhanden sind. Das ist mächtig, aber ohne Dry-Run schnell gefährlich.
Verifizieren: Verwende bei Löschszenarien immer zuerst --dry-run mit denselben Optionen und prüfe, welche Dateien betroffen wären.
Schritt 6: Ergebnis prüfen und wiederholbar machen
Ein guter rsync-Befehl ist nicht nur einmal erfolgreich, sondern später erneut nachvollziehbar. Halte deshalb den genutzten Befehl sauber fest, etwa in einem Skript oder in deiner Doku.
Wenn du Zielrechte prüfen musst, passt unsere Anleitung Linux-Benutzer, Gruppen und Rechte verstehen.
Verifizieren: Der Schritt ist erfolgreich, wenn du den Befehl wiederholen könntest, ohne erneut raten zu müssen, welche Pfade oder Optionen gemeint waren.
Troubleshooting
- Dateien landen im falschen Unterordner: Meist stimmt der Slash bei Quelle oder Ziel nicht.
- Permission denied: Rechte auf Quelle oder Ziel prüfen.
- SSH fragt immer wieder nach Passwörtern: Schlüssel-Login prüfen.
Häufige Fragen
Warum ist der Dry-Run so wichtig?
Weil du damit die Wirkung des Befehls prüfen kannst, bevor Daten verändert oder gelöscht werden.
Ist rsync ein Backup?
Es kann Teil einer Backup-Strategie sein, ersetzt aber kein vollständiges Backup-Konzept mit Versionierung und Rücksicherungstests.
Wann nutze ich --delete?
Nur wenn das Ziel wirklich ein exaktes Abbild der Quelle werden soll.
Fazit
rsync ist eines der stärksten Standardwerkzeuge für Linux-Admins, wenn es um nachvollziehbare Synchronisierung geht. Die eigentliche Sicherheit kommt dabei aus der Reihenfolge: SSH prüfen, Pfade verstehen, Dry-Run ausführen, erst dann wirklich synchronisieren.
Weiterführende Anleitungen und Quellen
- SSH-Key-Authentifizierung einrichten
- Linux-Benutzer, Gruppen und Rechte verstehen
- Festplatten unter Linux einbinden
Quellen: rsync man page, OpenSSH documentation.