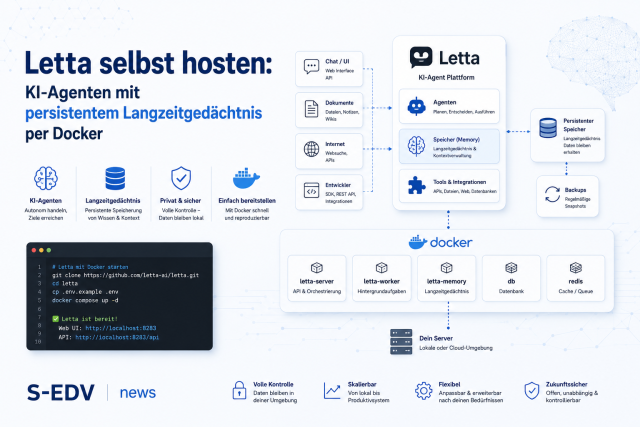
OpenHands als selbst gehosteten KI-Coding-Agenten einrichten (Docker + Ollama)
OpenHands löst GitHub-Issues selbstständig, schreibt Tests und erstellt Pull Requests – alles in einem Docker-Container, wahlweise mit lokalem Ollama-Backend ohne Cloud-Abhängigkeit. Diese Anleitung zeigt, wie du den KI-Coding-Agenten in 30 Minuten einrichtest.
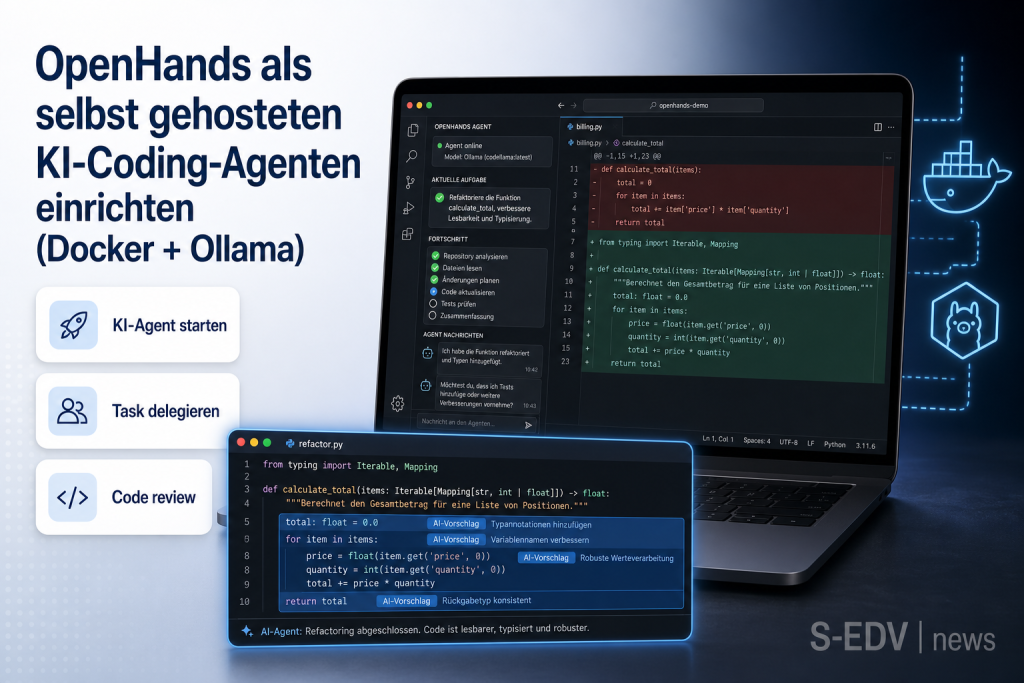
Stell dir vor, du weist einem GitHub-Issue das Label fix-me zu – und eine Stunde später liegt ein fertiger Pull Request vor, inklusive Tests und Refactoring. Genau das leistet OpenHands (ehemals OpenDevin): ein quelloffener KI-Coding-Agent, der eigenständig Code liest, schreibt, ausführt und beobachtet. Mit 74.400+ GitHub-Stars, einem SWE-Bench-Score von 77,6 und MIT-Lizenz ist er der stärkste Open-Source-Vertreter seiner Klasse. Wer das lokale Ollama-Backend einsetzt, betreibt den gesamten Stack datenschutzkonform auf eigener Hardware – ohne ein einziges Byte an Cloud-Dienste zu senden. Diese Anleitung führt dich in rund 30 Minuten von einem leeren Linux-Server zur laufenden OpenHands-Instanz mit Ollama-Backend.
Voraussetzungen
- Betriebssystem: Linux-Server oder -PC (Ubuntu 22.04/24.04 oder Debian 12 empfohlen)
- GPU: NVIDIA-Grafikkarte mit mindestens 8 GB VRAM (GTX 1080 Ti für
qwen2.5-coder:7b; 16 GB für:14b; 24 GB fürqwen3.6:35b-a3b) - Docker Engine: Version 24 oder neuer, inkl.
docker compose-Plugin - NVIDIA Container Toolkit: für GPU-Zugriff aus Docker-Containern (
nvidia-container-toolkit) - Ollama: aktuelle Version, installiert auf dem Host-System
- Freier Speicherplatz: 10–25 GB für Modelle, je nach Modellwahl
- Internetzugang: für den ersten Docker-Pull und
ollama pull(danach offline-fähig) - GitHub-Account: optional, nur für den Issue-Resolver benötigt
Schritt 1: Ollama mit korrektem Kontextfenster starten
Bevor OpenHands auch nur eine Zeile Code sieht, muss Ollama korrekt konfiguriert sein. Der entscheidende Punkt: Das Standard-Kontextfenster von Ollama beträgt 4.096 Tokens – der Systemprompt von OpenHands allein überschreitet diesen Wert. Ohne die folgende Einstellung hängt der Agent sofort beim ersten Request.
# Ollama installieren (falls noch nicht vorhanden)
curl -fsSL https://ollama.com/install.sh | sh
# Ollama mit erweitertem Kontext starten – PFLICHTSCHRITT
OLLAMA_CONTEXT_LENGTH=32768 \
OLLAMA_HOST=0.0.0.0:11434 \
OLLAMA_KEEP_ALIVE=-1 \
ollama serve &Die drei Variablen im Überblick: OLLAMA_CONTEXT_LENGTH=32768 setzt das Kontextfenster auf 32.768 Tokens (Minimum: 22.000). OLLAMA_HOST=0.0.0.0:11434 macht Ollama aus dem Docker-Netzwerk erreichbar. OLLAMA_KEEP_ALIVE=-1 verhindert, dass Ollama das Modell nach 5 Minuten Inaktivität aus dem VRAM entlädt – bei langen Agent-Tasks sonst ein echter Performance-Killer.
Anschließend das gewünschte Modell laden:
# Empfehlung für 16 GB VRAM (RTX 3080/4080)
ollama pull qwen2.5-coder:14b
# Oder für 24 GB VRAM (RTX 3090/4090) – offizielle Top-Empfehlung
ollama pull qwen3.6:35b-a3bVerifizieren: ollama list zeigt das heruntergeladene Modell. curl http://localhost:11434/api/tags gibt eine JSON-Antwort mit dem Modell-Eintrag zurück.
Schritt 2: Modellwahl – welche GPU brauche ich wirklich?
Die Modellwahl hängt direkt vom verfügbaren VRAM ab. Unterschreitung führt zur CPU-Auslagerung, was Stunden statt Minuten pro Task bedeutet. Die folgende Tabelle zeigt die verifizierten Werte aus der Ollama-Bibliothek:
Modell (ollama pull …) | Größe (Disk) | Empf. VRAM | Kontext | Zielgruppe |
|---|---|---|---|---|
qwen2.5-coder:7b | 4,7 GB | 8 GB | 32K | Einsteiger / ältere GPU |
qwen2.5-coder:14b | 9,0 GB | 16 GB | 32K | Empfehlung für den Alltag |
qwen2.5-coder:32b | 20 GB | 24 GB | 32K | Profis / RTX 4090 |
qwen3.6:27b | 17 GB | 20 GB | 256K | Große Codebases |
qwen3.6:35b-a3b | 24 GB | 24 GB+ | 256K | Offizielle Top-Empfehlung |
Wer keine passende GPU besitzt, kann OpenHands alternativ mit einem Cloud-API-Key (OpenAI, Anthropic) betreiben – dann reicht jede CPU-Maschine. Mehr zur lokalen Modellauswahl findest du in der Anleitung Ollama-Modelle 2026 richtig auswählen: VRAM, Quantisierung und Modellvergleich.
Schritt 3: OpenHands per Docker starten
Der einfachste Einstieg ist ein einzelner docker run-Befehl. Zwei Mounts sind dabei Pflicht: der Docker-Socket (/var/run/docker.sock), damit OpenHands den Sandbox-Container dynamisch starten kann, und das Konfigurations-Verzeichnis (~/.openhands) für persistente Einstellungen.
export SANDBOX_VOLUMES="$PWD:/workspace"
docker run -it --rm --pull=always \
-e AGENT_SERVER_IMAGE_REPOSITORY=ghcr.io/openhands/agent-server \
-e AGENT_SERVER_IMAGE_TAG=1.19.1-python \
-e SANDBOX_USER_ID=$(id -u) \
-e SANDBOX_VOLUMES=$SANDBOX_VOLUMES \
-e LLM_MODEL="openai/qwen2.5-coder:14b" \
-e LLM_BASE_URL="http://host.docker.internal:11434/v1" \
-e LLM_API_KEY="ollama" \
-v /var/run/docker.sock:/var/run/docker.sock \
-v ~/.openhands:/.openhands \
--add-host host.docker.internal:host-gateway \
-p 3000:3000 \
--name openhands \
docker.openhands.dev/openhands/openhands:1.7Drei Punkte verdienen besondere Aufmerksamkeit: Erstens muss LLM_MODEL zwingend das Präfix openai/ tragen – ohne dieses Präfix scheitert LiteLLM beim Verbindungsaufbau zu Ollama. Zweitens ist LLM_API_KEY ein Pflichtfeld, obwohl der Wert beliebig ist (hier: ollama). Drittens ist --add-host host.docker.internal:host-gateway auf Linux notwendig, weil diese Hostname-Auflösung nur auf macOS und Windows automatisch funktioniert.
Die Variable SANDBOX_USER_ID=$(id -u) sorgt dafür, dass der Sandbox-Container Dateien mit deiner Benutzer-ID anlegt. Ohne diese Einstellung entstehen Root-eigene Dateien im Workspace, die du danach nicht ohne sudo bearbeiten kannst.
Verifizieren: Nach dem Start öffnest du http://localhost:3000 im Browser. Die Web-Oberfläche zeigt ein Chat-Interface. Gib einen einfachen Test-Task ein, z. B. „Erstelle eine Datei hello.py mit Hello-World-Ausgabe" – der Agent sollte innerhalb weniger Sekunden die Datei im Workspace anlegen.
Schritt 4: Ollama + OpenHands als Docker-Compose-Stack
Für den dauerhaften Betrieb empfiehlt sich ein docker-compose.yml, das Ollama und OpenHands gemeinsam verwaltet. Damit entfällt das manuelle Starten von Ollama auf dem Host.
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
ports:
- "11434:11434"
volumes:
- ollama-data:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0:11434
- OLLAMA_CONTEXT_LENGTH=32768
- OLLAMA_KEEP_ALIVE=-1
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
openhands:
image: docker.openhands.dev/openhands/openhands:1.7
ports:
- "3000:3000"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ~/.openhands:/.openhands
- ./workspace:/workspace
environment:
- AGENT_SERVER_IMAGE_REPOSITORY=ghcr.io/openhands/agent-server
- AGENT_SERVER_IMAGE_TAG=1.19.1-python
- SANDBOX_USER_ID=1000
- SANDBOX_VOLUMES=/workspace:/workspace
- LLM_MODEL=openai/qwen2.5-coder:14b
- LLM_BASE_URL=http://ollama:11434/v1
- LLM_API_KEY=ollama
extra_hosts:
- "host.docker.internal:host-gateway"
depends_on:
- ollama
volumes:
ollama-data:Im Compose-Stack zeigt LLM_BASE_URL auf http://ollama:11434/v1 – also den Ollama-Service-Namen statt host.docker.internal, da beide Container im selben Docker-Netzwerk laufen.
# Stack starten
docker compose up -d
# Modell in den laufenden Ollama-Container laden
docker exec -it <ollama-container-name> ollama pull qwen2.5-coder:14bVerifizieren: docker compose ps zeigt beide Services als running. docker logs openhands sollte keine Verbindungsfehler enthalten.
Schritt 5: CLI-Modus für Automatisierung und CI/CD
Wer OpenHands in Pipelines oder von der Kommandozeile aus nutzen möchte, kann den Agenten auch ohne Docker direkt per pip/uv installieren:
# Installation (empfohlen: uv für schnelle Abhängigkeitsauflösung)
pip install uv && uv tool install openhands --python 3.12
# Konfigurationsdatei anlegen
mkdir -p ~/.openhands
cat > ~/.openhands/agent_settings.json <<'EOF'
{
"llm": {
"model": "openai/qwen2.5-coder:14b",
"api_key": "ollama",
"base_url": "http://localhost:11434/v1"
}
}
EOF
# Aufgabe stellen (interaktiv)
openhands -t "Schreibe Unit-Tests fuer src/auth.py und behebe den gefundenen Bug"
# Headless fuer CI (bestaetigt alle Aktionen automatisch – nur in kontrollierten Umgebungen!)
openhands --headless --json -t "Refaktoriere utils.py" > output.jsonl
# Letzten Task fortsetzen
openhands --resume --lastDer --headless-Modus ist mächtig, aber gefährlich: Er genehmigt sämtliche Datei-Schreib- und Ausführaktionen ohne Rückfrage. Setze ihn ausschließlich in isolierten CI-Umgebungen mit kontrollierten Zugangsdaten ein – nie auf Produktionssystemen mit echten Secrets.
Schritt 6: GitHub-Issue-Resolver einrichten
Das eigentliche Versprechen von OpenHands ist der nahtlose GitHub-Workflow: Du eröffnest ein Issue, gibst einen kurzen Kontext, setzt das Label fix-me – und OpenHands liest das Issue, analysiert den Code, schreibt den Fix und öffnet einen Pull Request.
Voraussetzung ist ein GitHub Actions Workflow im Repository. Die nötigen Secrets (LLM_MODEL, LLM_API_KEY) trägst du in den Repository-Einstellungen unter „Secrets and variables → Actions" ein. Über Repository-Variablen lassen sich weitere Parameter steuern:
| Variable | Bedeutung | Beispielwert |
|---|---|---|
LLM_MODEL | Modell inkl. Präfix | openai/qwen2.5-coder:14b |
OPENHANDS_MAX_ITER | Max. Agent-Iterationen | 50 |
TARGET_BRANCH | Zielbranch für PRs | main |
TARGET_RUNNER | GitHub-Runner-Label | ubuntu-latest |
Wichtiger Unterschied zwischen den zwei Auslösern: Das Label fix-me an einem Issue löst das gesamte Issue als Task aus. Der Kommentar @openhands-agent beschränkt den Kontext auf den spezifischen Kommentarinhalt – nützlich, wenn du dem Agenten eine präzise Teilaufgabe stellen willst.
Für den Aufbau vollständiger CI/CD-Pipelines mit Automatisierungsworkflows lohnt sich ein Blick auf n8n mit Docker: KI-Workflows und Automatisierung self-hosted.
Deployment-Varianten im Überblick
| Variante | Befehl | Port | Cloud-Abhängigkeit | Anwendungsfall |
|---|---|---|---|---|
| Docker (Web-UI) | docker run … :1.7 | 3000 | Nein | Standard-Setup |
| Docker Compose | docker compose up | 3000 | Nein | Ollama-Stack gemeinsam |
| CLI (pip/uv) | openhands -t "…" | – | Nein | Terminal / lokales CI |
| Headless | openhands --headless | – | Nein | GitHub Actions |
| OpenHands Cloud | cloud.all-hands.dev | – | Ja | Kein Setup nötig |
Troubleshooting / Typische Fehler
Ollama-Kontextfenster zu klein
Symptom: Der Agent hängt sofort nach dem ersten Request, die Logs zeigen Fehler wie „context length exceeded". Ursache: Ollama läuft ohne OLLAMA_CONTEXT_LENGTH=32768. Lösung: Ollama stoppen, mit der Umgebungsvariable neu starten und den Docker-Container ebenfalls neu starten.
Docker-Socket nicht gemountet
Symptom: OpenHands startet, kann aber keine Tasks ausführen – Logs zeigen „cannot connect to Docker daemon". Ursache: -v /var/run/docker.sock:/var/run/docker.sock fehlt im docker run-Befehl. Das ist der häufigste Fehler beim ersten Start. Den Mount nachrüsten und den Container neu erstellen.
host.docker.internal nicht auflösbar (Linux)
Symptom: OpenHands kann Ollama nicht erreichen, Fehlermeldung „Connection refused" für host.docker.internal:11434. Ursache: Auf Linux ist dieser Hostname nicht automatisch verfügbar. Lösung: --add-host host.docker.internal:host-gateway zum docker run-Befehl hinzufügen.
LLM_MODEL-Präfix fehlt
Symptom: Fehlermeldung „LiteLLM: Provider not found" oder ähnlich. Ursache: Das Modell wurde ohne das Präfix openai/ angegeben (z. B. nur qwen2.5-coder:14b statt openai/qwen2.5-coder:14b). LiteLLM kann ohne dieses Präfix den OpenAI-kompatiblen Endpunkt von Ollama nicht ansprechen.
VRAM-Engpass bei großen Modellen
Symptom: Tasks dauern Stunden statt Minuten, nvidia-smi zeigt kaum VRAM-Auslastung. Ursache: Das Modell wurde auf die CPU ausgelagert, weil der VRAM nicht ausreichte. Lösung: Ein kleineres Modell wählen oder VRAM freigeben.
Agent bricht zu früh ab
Symptom: Bei komplexen Tasks stoppt OpenHands mit „Max iterations reached". Ursache: OPENHANDS_MAX_ITER ist zu niedrig. Im GitHub-Actions-Workflow als Repository-Variable erhöhen; beim direkten Docker-Start als Umgebungsvariable übergeben.
Root-Dateien im Workspace
Symptom: Neu erstellte Dateien gehören root und können ohne sudo nicht bearbeitet werden. Ursache: SANDBOX_USER_ID=$(id -u) wurde nicht gesetzt. Container entfernen, Variable ergänzen und neu starten.
Häufige Fragen
Läuft OpenHands vollständig ohne Internet?
Ja – sobald das Docker-Image und das Ollama-Modell einmalig heruntergeladen sind, braucht weder OpenHands noch Ollama eine Internetverbindung während der Nutzung. Nur der erste docker pull und ollama pull setzen Netz voraus.
Welches Modell ist der beste Einstieg für 16 GB VRAM?
qwen2.5-coder:14b (9 GB Disk, 32K Kontext). Es läuft komfortabel auf einer RTX 3080 oder 4080 und liefert zuverlässige Ergebnisse für Standard-Coding-Tasks. Wer regelmäßig mit großen Codebases arbeitet, sollte mittelfristig auf qwen3.6:27b mit 256K-Kontext wechseln.
Wie viel Hardware brauche ich wirklich?
Für den Einstieg reicht eine GTX 1080 Ti (8 GB VRAM, Gebrauchtmarkt ab etwa 150 EUR) für das 7b-Modell. Für produktive Nutzung empfiehlt sich eine RTX 3090 (24 GB, ~500 EUR gebraucht). Alternativ lässt sich OpenHands mit einem Cloud-API-Key betreiben – dann genügt jede CPU-Maschine, allerdings ohne Datenschutzvorteil.
Funktionieren auch andere lokale Modelle außer Qwen?
Ja – jedes Ollama-kompatible Modell mit Function-Calling/Tool-Use-Unterstützung funktioniert. Community-erprobte Alternativen sind devstral-small-2:24b und qwopus3.5-27b. Stark quantisierte Modelle (Q2) neigen im Agent-Loop zu Halluzinationen und sollten vermieden werden.
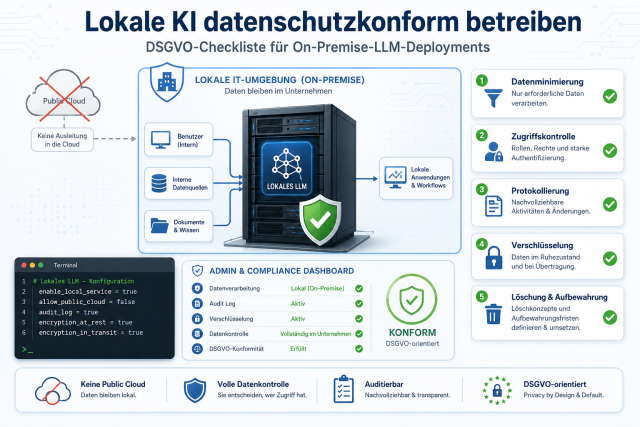
Ist OpenHands DSGVO-konform betreibbar?
Bei vollständig lokalem Betrieb mit Ollama werden keine Daten an externe Dienste übermittelt. Das macht den Stack grundsätzlich DSGVO-konform. Eine vollständige Datenschutzbewertung hängt jedoch von deiner konkreten Infrastruktur und den verarbeiteten Daten ab. Hinweise zur datenschutzkonformen LLM-Einrichtung findest du in der Anleitung Lokale KI datenschutzkonform betreiben: DSGVO-Checkliste für On-Premise-LLM-Deployments.
Was unterscheidet Web-UI und CLI-Modus?
Die Web-UI (Port 3000) bietet eine grafische Chat-Oberfläche für interaktive Nutzung mit Dateivorschau und Task-Verlauf. Der CLI-Modus ist für Automatisierung und CI/CD gedacht: Mit --headless lädt er kein UI und bestätigt alle Aktionen automatisch – was in unkontrollierten Umgebungen ein Sicherheitsrisiko darstellt.
Welche Enterprise-Features gibt es in der MIT-Version nicht?
Fortgeschrittene Multi-Agenten-Orchestrierung, SSO und bestimmte Team-Features befinden sich im enterprise/-Verzeichnis des Repositories und unterliegen einer proprietären Lizenz. Für privaten und KMU-Einsatz ist die MIT-Kernlizenz vollständig ausreichend.
Fazit
OpenHands ist kein Spielzeug mehr. Mit einem SWE-Bench-Score von 77,6 löst der Agent reale GitHub-Issues zuverlässiger als die meisten alternativen Open-Source-Lösungen. Der Docker-basierte Aufbau ist in 30 Minuten lauffähig – vorausgesetzt, man kennt die drei häufigsten Fallstricke: fehlender Docker-Socket-Mount, fehlendes openai/-Präfix im Modellnamen und zu kleines Ollama-Kontextfenster. Wer diese drei Punkte beherzigt, bekommt einen autonomen Coding-Agenten, der GitHub-Issues selbstständig von der Analyse bis zum Pull Request durchzieht – vollständig auf eigener Hardware, ohne Cloud-Abhängigkeit und datenschutzkonform.
Für den Einstieg in das breitere Ökosystem lokaler KI-Tools empfiehlt sich außerdem ein Blick auf Ollama und Open WebUI mit Docker: eigenes lokales KI-Sprachmodell ohne Cloud betreiben sowie auf Continue.dev: GitHub Copilot selbst hosten in VS Code und JetBrains mit Ollama als direkter Coding-Assistent im Editor.
Weiterführende Anleitungen und Quellen
- Ollama und Open WebUI mit Docker: eigenes lokales KI-Sprachmodell ohne Cloud betreiben
- Continue.dev: GitHub Copilot selbst hosten in VS Code und JetBrains mit Ollama
- Ollama-Modelle 2026 richtig auswählen: VRAM, Quantisierung und Modellvergleich für KMU
- Lokale KI datenschutzkonform betreiben: DSGVO-Checkliste für On-Premise-LLM-Deployments
- OpenHands Offizielle Dokumentation – Local LLMs
- OpenHands GitHub Repository
- Ollama Modell-Bibliothek – qwen2.5-coder