Strukturierte JSON-Ausgaben aus lokalen LLMs: Grammar-Constraints und JSON-Mode für zuverlässige Automatisierungen
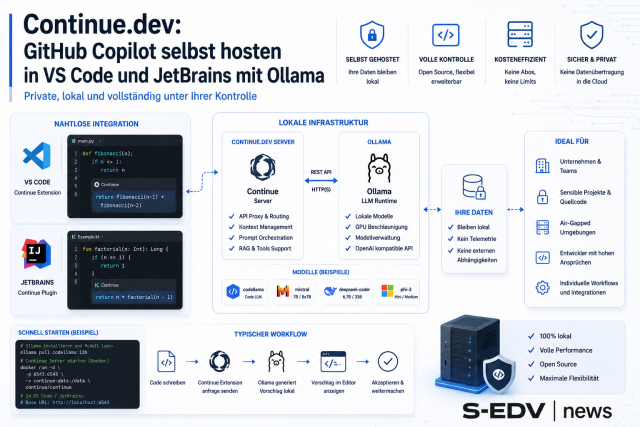
Wer lokale LLMs in n8n-Workflows oder PowerShell-Skripte einbinden will, scheitert oft an unzuverlässigen Ausgaben. Mit Grammar-Sampling in llama.cpp und dem nativen JSON-Schema-Mode von Ollama erzwingst du exakt strukturierte JSON-Antworten – ohne manuelle Nachbearbeitung.

Lokale LLMs sind in vielen KMU-Umgebungen längst kein Experiment mehr – sie übernehmen Aufgaben wie Textzusammenfassung, Datenextraktion und Klassifizierung direkt auf eigener Hardware. Das Problem: Ohne Einschränkungen liefern diese Modelle freien Text, der manchmal JSON-ähnlich aussieht, aber selten maschinenlesbar und reproduzierbar ist. Diese Anleitung zeigt dir zwei praxiserprobte Wege, wie du llama.cpp per Grammar-Sampling und Ollama per nativem JSON-Schema-Mode zu garantiert strukturierten Ausgaben zwingst – direkt einsetzbar in PowerShell-Skripten, n8n-Workflows und Python-Pipelines.
Voraussetzungen
- Lokale Hardware: mindestens 8 GB RAM für CPU-Inferenz; empfohlen 8–16 GB VRAM für GPU-Inferenz (NVIDIA CUDA oder AMD ROCm)
- llama.cpp Binary-Release von github.com/ggml-org/llama.cpp/releases oder selbst kompiliert
- Ollama von ollama.com (Windows, macOS oder Linux, nativ oder per Docker)
- GGUF-Modelldatei, z. B. Llama 3.1 8B Q4_K_M (von HuggingFace oder Ollama-Registry)
- Python 3.9+ mit
pip install ollama pydantic(für Python-Workflows) - PowerShell 7+ (unter Windows 10/11 vorinstalliert oder von microsoft.com/powershell)
- curl (in Windows 10/11 vorinstalliert) für API-Tests
- n8n (lokal per npm/Docker oder Cloud) für Workflow-Automatisierung
| Modell | Größe | Quantisierung | VRAM (ca.) | Kontext | Lizenz |
|---|---|---|---|---|---|
| Llama 3.1 8B | 8B | Q4_K_M | 5–6 GB | 128k | Llama 3 Community |
| Llama 3.2 3B | 3B | Q4_K_M | 2–3 GB | 128k | Llama 3 Community |
| Qwen2.5 7B | 7B | Q4_K_M | ~5 GB | 32k | Apache 2.0 |
| Qwen3 8B | 8B | Q4_K_M | 5–6 GB | 128k | Apache 2.0 |
| Gemma 4 4B | 4B | Q4_K_M | 3–4 GB | 128k | Gemma ToS |
| Mistral-Nemo 12B | 12B | Q4_K_M | 8–9 GB | 128k | Apache 2.0 |
Schritt 1: Das Prinzip verstehen – wie Grammar-Constraints wirklich funktionieren
Bevor du die ersten API-Aufrufe absetzt, lohnt sich ein kurzer Blick unter die Haube. Der entscheidende Unterschied zu Prompt-Engineering-Tricks wie „Antworte nur als JSON" liegt darin, wo die Einschränkung greift.
Bei Grammar-Sampling in llama.cpp wird nach jedem generierten Token geprüft, welche Folge-Token mit der aktiven Grammatik vereinbar sind. Alle anderen Token werden aus dem Sampling ausgeschlossen – das Modell kann keine invalide Struktur erzeugen, weil es schlicht keine Wahl hat. Das Schema wird dabei nicht in den Prompt eingefügt; das Modell sieht es nicht. Die Beschränkung wirkt ausschließlich im Sampler während der Generierung.
Ollama nutzt dasselbe Prinzip unter der Bezeichnung „Constrained Decoding". Seit dem 6. Dezember 2024 akzeptiert der format-Parameter entweder den String "json" (valides JSON, Struktur aber frei wählbar) oder ein vollständiges JSON-Schema-Objekt für strikte Strukturvorgaben.
Eine wichtige Konsequenz: Weil das Modell das Schema nicht direkt sieht, musst du trotzdem im Prompt erklären, welche Daten du erwartest. Der Sampler sorgt für die Form, der Prompt für den Inhalt.
Schritt 2: llama.cpp-Server starten und mit JSON-Schema abfragen
Lade dir das aktuelle Binary-Release von llama.cpp herunter und starte den Server. Der Server läuft standardmäßig auf Port 8080 und ist OpenAI-API-kompatibel.
# Basis-Start (Port 8080, CPU) ./llama-server -m models/llama-3.1-8b-q4_k_m.gguf -c 4096 # Mit GPU-Offload (NVIDIA, 35 Layer auf GPU) ./llama-server -m models/llama-3.1-8b-q4_k_m.gguf -c 4096 -ngl 35Zum schnellen Test über die CLI (ohne Server) nutzt du den -j-Flag mit einem JSON-Schema direkt:
./llama-cli -m models/llama-3.1-8b-q4_k_m.gguf \ -j '{"type":"object","properties":{"name":{"type":"string"},"age":{"type":"integer"}},"required":["name","age"]}' \ -p "Extrahiere Name und Alter aus: Max Mustermann, 34 Jahre"Für den Server-Betrieb sendest du das Schema im POST-Body an den /completion-Endpunkt:
curl http://localhost:8080/completion \ -H "Content-Type: application/json" \ -d '{ "prompt": "Extrahiere Name und Alter aus: Max Mustermann, 34 Jahre", "json_schema": { "type": "object", "properties": { "name": {"type": "string"}, "age": {"type": "integer"} }, "required": ["name", "age"] }, "stream": false }'Für OpenAI-kompatible Clients nutzt du den /v1/chat/completions-Endpunkt mit response_format:
curl http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer no-key" \ -d '{ "model": "local-model", "response_format": { "type": "json_schema", "schema": { "type": "object", "properties": { "name": {"title": "Name", "type": "string"}, "date": {"title": "Date", "type": "string"}, "participants": { "title": "Participants", "type": "array", "items": {"type": "string"} } }, "required": ["name", "date", "participants"] } }, "messages": [ {"role": "user", "content": "Extrahiere Meeting-Daten: Projektmeeting am 15.06.2026 mit Anna und Bob"} ], "stream": false }'Verifizieren: Die Antwort enthält unter content ein valides JSON-Objekt mit exakt den definierten Feldern. Fehlende Pflichtfelder oder freier Text außerhalb der JSON-Struktur sind physikalisch ausgeschlossen.
Schritt 3: GBNF-Grammatiken – wenn JSON-Schema nicht reicht
GBNF (GGML BNF) ist eine Erweiterung der Backus-Naur-Form und ermöglicht vollständige Kontrolle über das Ausgabeformat – auch für Nicht-JSON-Formate wie CSV, Markdown-Tabellen oder proprietäre Protokolle. llama.cpp konvertiert JSON-Schemas intern zu GBNF; für eigene Formate schreibst du die Grammatik direkt.
# grammars/person.gbnf root ::= object object ::= "{" ws name-pair "," ws age-pair "}" ws name-pair ::= "\"name\"" ws ":" ws string age-pair ::= "\"age\"" ws ":" ws number string ::= "\"" [a-zA-Z ]+ "\"" number ::= [0-9]+ ws ::= [ \t\n]*Die Grammatik-Datei übergibst du per Flag:
./llama-cli -m models/llama-3.1-8b-q4_k_m.gguf \ --grammar-file grammars/person.gbnf \ -p "Erstelle ein Personen-Objekt für Max Mustermann, 34 Jahre"Wenn du ein bestehendes JSON-Schema als GBNF-Datei brauchst, nutze das mitgelieferte Hilfsskript:
python3 examples/json_schema_to_grammar.py schema.json > output.gbnfUnterstützte JSON-Schema-Typen in llama.cpp: string, integer, object, array, boolean, null, minLength/maxLength, minimum/maximum (nur Integer), required, minItems/maxItems. Nicht unterstützt: uniqueItems, contains, not, Conditionals und Remote-$ref.
Schritt 4: Ollama JSON-Schema-Mode einrichten
Ollama bietet den einfachsten Einstieg, weil kein separates Binary nötig ist. Nach dem Start mit ollama serve (bzw. automatisch im Hintergrund) sendest du Anfragen an Port 11434.
Wichtig: Verwende nicht den einfachen format: "json"-Mode für zuverlässige Automatisierungen – er erzwingt nur valides JSON, aber keine definierte Struktur. Nutze stattdessen das vollständige Schema-Objekt:
curl http://localhost:11434/api/chat \ -H "Content-Type: application/json" \ -d '{ "model": "llama3.1", "messages": [ {"role": "user", "content": "Extrahiere Daten: Max Mustermann, 34 Jahre, Berlin"} ], "format": { "type": "object", "properties": { "name": {"type": "string"}, "age": {"type": "integer"}, "city": {"type": "string"} }, "required": ["name", "age", "city"] }, "stream": false }'Verifizieren: Die Antwort enthält unter message.content ein JSON-Objekt mit den drei Pflichtfeldern. Du kannst es direkt mit jq '.message.content | fromjson' parsen.
Schritt 5: Python-Integration mit Pydantic
Für Python-Workflows kombiniert Pydantic Schema-Generierung und Validierung in einem Schritt. Die Field(description=...)-Annotation verbessert dabei nachweislich die Modell-Genauigkeit, weil das Modell zumindest im Prompt die Bedeutung der Felder kennt.
from ollama import chat from pydantic import BaseModel, Field class Person(BaseModel): name: str = Field(description="Vollständiger Name der Person") age: int = Field(description="Alter in Jahren") city: str = Field(description="Wohnort") response = chat( model='llama3.1', messages=[{ 'role': 'user', 'content': 'Extrahiere: Max Mustermann, 34 Jahre, Berlin' }], format=Person.model_json_schema(), options={"temperature": 0} ) person = Person.model_validate_json(response.message.content) print(f"{person.name}, {person.age} Jahre, {person.city}")Verifizieren: Das Skript gibt „Max Mustermann, 34 Jahre, Berlin" aus. Bei Typ-Fehlern wirft model_validate_json() einen ValidationError – das ist die Absicherung für den Produktivbetrieb.
Schritt 6: PowerShell-Integration für Windows-Admins
Für Windows-Admins ist PowerShell der direkteste Weg. Invoke-RestMethod gibt das geparste JSON als PSCustomObject zurück; ConvertTo-Json -Depth 10 -Compress ist für verschachtelte Schemas zwingend erforderlich.
$schema = @{ type = "object" properties = @{ name = @{ type = "string" } age = @{ type = "integer" } city = @{ type = "string" } } required = @("name", "age", "city") } $body = @{ model = "llama3.1" messages = @( @{ role = "user"; content = "Extrahiere: Max Mustermann, 34 Jahre, Berlin" } ) format = $schema stream = $false } | ConvertTo-Json -Depth 10 -Compress $response = Invoke-RestMethod ` -Uri "http://localhost:11434/api/chat" ` -Method Post ` -ContentType "application/json" ` -Body $body $data = $response.message.content | ConvertFrom-Json Write-Host "Name: $($data.name), Alter: $($data.age), Stadt: $($data.city)"Verifizieren: Die Ausgabe zeigt „Name: Max Mustermann, Alter: 34, Stadt: Berlin". Das $data-Objekt lässt sich direkt weiterverarbeiten – kein String-Parsing, kein Regex nötig.
Schritt 7: n8n-Workflow-Integration
In n8n bindest du Ollama oder den llama.cpp-Server über den HTTP-Request-Node ein. Die Antwort ist danach in folgenden Nodes direkt als strukturiertes Objekt verfügbar.
Node-Konfiguration für Ollama:
- Node-Typ: HTTP Request
- Method: POST
- URL:
http://localhost:11434/api/chat - Body (JSON):
{ "model": "llama3.1", "messages": [ {"role": "user", "content": "{{ $json.input_text }}"} ], "format": { "type": "object", "properties": { "result": {"type": "string"}, "confidence": {"type": "number"} }, "required": ["result", "confidence"] }, "stream": false }Im nächsten Node erreichst du die Antwort über {{ $json.message.content }} (Ollama-API) bzw. {{ $json.choices[0].message.content }} (OpenAI-kompatibles Format). Verwechsle die beiden Pfade nicht – das ist der häufigste Fehler bei n8n-LLM-Integrationen.
Für mehr zu n8n-Workflows mit lokalen KI-Modellen empfiehlt sich die Anleitung n8n mit Docker: KI-Workflows und Automatisierung self-hosted.
Methoden im Vergleich
| Methode | Tool | Endpunkt / Flag | Struktur garantiert | Modell sieht Schema | Geeignet für |
|---|---|---|---|---|---|
| GBNF-Grammatik (manuell) | llama.cpp | --grammar / --grammar-file | Ja (Sampler) | Nein | Vollständige Kontrolle, Nicht-JSON |
| JSON-Schema zu GBNF | llama.cpp CLI | --json / -j | Ja (Sampler) | Nein | JSON-Extraktion, Skripte |
| json_schema im Server | llama.cpp-Server | POST /completion | Ja | Nein | REST-Integration, n8n |
| response_format (OpenAI) | llama.cpp-Server | POST /v1/chat/completions | Ja | Nein | OpenAI-kompatible Clients |
| format: "json" | Ollama | /api/generate, /api/chat | Nur valides JSON | Nein | Einfache JSON-Rückgaben |
| format: {schema} | Ollama | /api/generate, /api/chat | Ja (nach Schema) | Nein | Automatisierungen, PowerShell |
| Pydantic + Ollama | Ollama + Python | ollama.chat() | Ja + validiert | Nein | Python-Workflows |
Troubleshooting / Typische Fehler
stream nicht auf false gesetzt
Der häufigste Fehler: Ohne "stream": false liefern Ollama und llama.cpp-Server NDJSON-Streams (zeilenweise Token-Pakete). Invoke-RestMethod und einfache curl-Auswertungen versagen dann. Immer explizit stream: false setzen.
format: "json" statt format: {schema-objekt}
Der einfache JSON-Mode (format: "json") garantiert nur valides JSON – nicht die gewünschten Felder. Für zuverlässige Automatisierungen immer das vollständige Schema-Objekt mit required-Array übergeben.
Schema fehlt im Prompt-Kontext
Das Modell sieht das Schema bei llama.cpp und Ollama nicht direkt. Ohne erklärender Prompt-Text fehlt der Kontext für Feldnamen und Bedeutungen. Beschreibe im Prompt immer natürlichsprachlich, welche Daten du erwartest – der Sampler sorgt für die Form, der Prompt für den Inhalt.
required-Array fehlt
Ohne required-Array im Schema sind alle Felder optional. Das Modell kann Felder weglassen, was Downstream-Code mit KeyError- oder Null-Fehlern bricht. Immer alle Pflichtfelder explizit aufführen.
Performance-Falle bei GBNF-Wiederholungen
Mehrfach optionale Elemente hintereinander (x? x? x?) führen zu exponentiell langsamem Sampling. Stattdessen x{0,N} oder verschachtelte Optionale verwenden.
Nicht unterstützte JSON-Schema-Features
In llama.cpp funktionieren uniqueItems, contains, not, Conditionals und Remote-$ref nicht. Das Skript schlägt dann lautlos fehl oder produziert unerwartete Grammatiken. Schemas vorher auf unterstützte Features prüfen.
Kontextlänge unterschätzt
Bei langen Dokumenten zur Extraktion auf ausreichend -c (llama.cpp) bzw. num_ctx (Ollama) achten. Wird der Kontext überschritten, wird das Dokument still abgeschnitten – das Modell arbeitet dann auf unvollständigen Daten.
n8n: falscher Antwortpfad
Bei Ollama-API ist das Ergebnis unter response.message.content, bei OpenAI-kompatiblem Format unter response.choices[0].message.content. Die Verwechslung führt zu leeren Feldern im Workflow.
Häufige Fragen
Funktioniert Grammar-Sampling mit jedem GGUF-Modell?
Ja, Grammar-Sampling in llama.cpp ist vollständig modellunabhängig. Es wirkt auf Sampler-Ebene und funktioniert mit jedem GGUF-Modell – unabhängig von Fine-Tuning oder Trainingsdaten. Selbst Modelle ohne JSON-Training profitieren davon.
Was ist der Unterschied zwischen format: "json" und format: {schema} in Ollama?
format: "json" erzwingt nur valides JSON ohne Strukturgarantie – die Felder können variieren und fehlen. format: {schema-objekt} erzwingt exakt die definierte Struktur mit allen required-Feldern. Für Automatisierungen ist immer das Schema-Objekt zu verwenden.
Muss ich Pydantic verwenden oder reicht reines JSON-Schema?
Pydantic ist optional, aber empfohlen: Es kombiniert Schema-Generierung (model_json_schema()) und Validierung (model_validate_json()) in einem Schritt. Alternativ kann ein Python-dict mit dem Schema-Objekt direkt als format-Wert übergeben werden.
Kann ich llama.cpp-Server und Ollama gleichzeitig in n8n nutzen?
Ja, beide stellen OpenAI-kompatible APIs bereit – llama.cpp auf Port 8080, Ollama auf Port 11434. In n8n den HTTP-Request-Node oder einen OpenAI-Credential-Node mit der jeweiligen Base-URL und einem Dummy-API-Key (no-key) konfigurieren.
Wie groß muss das Modell für zuverlässige strukturierte Ausgaben sein?
Ab etwa 7–8 Milliarden Parametern (Q4_K_M) sind die Ergebnisse für einfache Extraktionsaufgaben sehr zuverlässig. Kleinere Modelle mit 3 Milliarden Parametern funktionieren für einfache Schemas, versagen aber bei komplexen verschachtelten Strukturen oder mehrstufigen Abhängigkeiten.
Wirkt das JSON-Schema auch als Ausgabe-Validierung?
Nein. Grammar-Sampling und Constrained Decoding sind reine Generierungsconstraints. Typ-Fehler (z. B. eine Zahl als String) können theoretisch noch auftreten. Für den Produktivbetrieb immer zusätzlich serverseitig validieren – mit Pydantic in Python oder einem JSON-Schema-Validator.
Unterstützt Cloud-Ollama (ollama.com) Structured Outputs?
Nein, Cloud-Ollama unterstützt Structured Outputs aktuell nicht. Diese Funktion ist ausschließlich im selbst gehosteten Ollama verfügbar.
Fazit
Grammar-Sampling in llama.cpp und Ollamas nativer JSON-Schema-Mode lösen das Kernproblem lokaler LLM-Integrationen: unzuverlässige, freie Textausgaben, die manuell nachbearbeitet werden müssen. Beide Ansätze arbeiten auf Sampler-Ebene und sind damit fundamentaler als Prompt-Engineering – das Modell kann die definierte Struktur schlicht nicht verlassen. Für Windows-Admins ist die PowerShell-Integration via Invoke-RestMethod sofort einsetzbar; für n8n-Workflows reicht der HTTP-Request-Node mit drei zusätzlichen Zeilen JSON. Python-Entwickler profitieren am stärksten von der Pydantic-Kombination, die Schema-Generierung und Validierung in einem Schritt liefert.
Wer tiefer in den lokalen KI-Stack einsteigen will, findet in der Anleitung Ollama-Modelle 2026 richtig auswählen: VRAM, Quantisierung und Modellvergleich eine fundierte Entscheidungshilfe für die Modellwahl. Für den nächsten Schritt – vollständige RAG-Pipelines mit Qualitätsmessung – empfiehlt sich RAG produktiv betreiben: Chunking, Hybrid-Search, Reranking und Antwortqualität messen.
Weiterführende Anleitungen und Quellen
- Ollama-Modelle 2026 richtig auswählen: VRAM, Quantisierung und Modellvergleich für KMU
- RAG produktiv betreiben: Chunking, Hybrid-Search, Reranking und Antwortqualität messen
- n8n mit Docker: KI-Workflows und Automatisierung self-hosted
- Lokales RAG-System mit Qdrant und Embeddings selbst bauen
- llama.cpp Grammars README (offiziell)
- Ollama Blog: Structured Outputs (offiziell)
- Ollama Docs: Structured Outputs
- llama.cpp Server README (offiziell)
- Ollama API Dokumentation (offiziell)
Passende Anleitungen auf S-EDV GPT-5.5-Cyber: OpenAI startet Sicherheitsmodell als Konkurrenz zu Anthropic Myth Anthropic veröffentlicht Claude Fable 5 und Mythos 5: Frontier-Modell mit Sicher Linux-Fileserver im Active Directory: Samba als Domain Member mit NTFS-ähnlichen