Letta selbst hosten: KI-Agenten mit persistentem Langzeitgedächtnis per Docker
Zustandslose Chatbots vergessen nach jedem Gespräch alles – Letta (ehemals MemGPT) löst das mit einem selbstverwalteten Drei-Stufen-Gedächtnis. Diese Anleitung zeigt, wie du den Letta-Server per Docker on-premise betreibst.
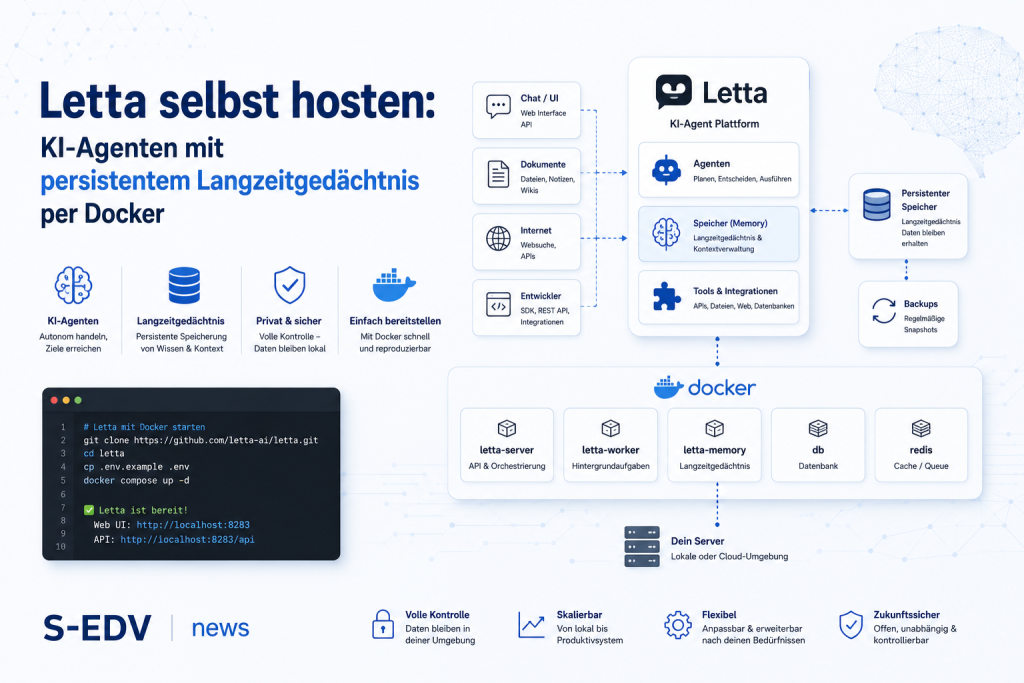
Konventionelle Chatbots beginnen jedes Gespräch auf einem leeren Blatt – kein Kontext aus früheren Sitzungen, keine Erinnerung an Nutzerpräferenzen, keine aufgebaute Wissensbasis. Für einfache Fragen reicht das aus; für Helpdesk-Agenten, Wissensassistenten oder länger laufende Automatisierungsprojekte ist es ein fundamentales Hindernis. Letta (früher bekannt als MemGPT) entstammt der akademischen Forschung und überträgt das Betriebssystem-Konzept der Speicherhierarchie auf KI-Agenten: Core Memory als schneller Arbeitsspeicher, Archival Memory als semantisch durchsuchbare Datenbank, Recall Memory als vollständiges Gesprächsarchiv. Das Docker-Image letta/letta:latest bündelt Python-Server und PostgreSQL mit pgvector in einem einzigen Container und läuft vollständig on-premise – ohne GPU, ohne Cloud-Abhängigkeit. Diese Anleitung richtet sich an IT-Profis und KMU-Admins, die zustandsbehaftete KI-Agenten selbst hosten und dabei die volle Kontrolle über ihre Daten behalten möchten.
Voraussetzungen
- Server oder VPS mit Ubuntu 22.04/24.04 LTS (mind. 2 GB RAM / 2 vCPU für Tests, 4 GB RAM / 4 vCPU für Produktion)
- Docker und Docker Compose Plugin installiert – siehe Docker und Docker Compose auf Linux installieren
- Mindestens 5 GB freier Festplattenplatz für Image, Datenbank und Backups
- LLM-API-Key (OpenAI, Anthropic) oder lokal installiertes Ollama mit einem Modell (Q5+-Quantisierung, z. B.
llama3.2:3b-instruct-q5_K_M) - Embedding-Modell: bei OpenAI automatisch verfügbar; bei Anthropic als alleinigem Provider ist ein separates Embedding-Modell (OpenAI oder Ollama
nomic-embed-text) zwingend erforderlich - Domain mit DNS-A-Record (für Produktionsbetrieb mit TLS)
opensslundcurlauf dem Host installiert
Schritt 1: Letta-Gedächtnisarchitektur verstehen
Bevor du den Container startest, lohnt ein Blick auf das Konzept – denn es erklärt, warum Letta sich grundlegend von einem einfachen ChatGPT-Wrapper unterscheidet.
Letta verwaltet drei Gedächtnisebenen eigenständig, ohne manuellen Eingriff:
- Core Memory – Der "RAM" des Agenten. Immer im aktiven Kontextfenster. Besteht aus editierbaren Blöcken (Label, Inhalt, Zeichenlimit). Der Agent kann diese Blöcke selbst beschreiben und aktualisieren – etwa Nutzerinfos, Projektstatus oder Präferenzen.
- Archival Memory – Die Vektordatenbank (pgvector). Kann beliebig groß wachsen; der Agent ruft Inhalte semantisch per
archival_memory_searchab und schreibt neue Einträge perarchival_memory_insert. Ideal für Wissensdatenbanken und Dokumentenarchive. - Recall Memory – Das vollständige, durchsuchbare Gesprächsarchiv. Alle vergangenen Nachrichten sind abrufbar; bei Kontextfenster-Überschreitung evakuiert Letta automatisch ca. 70 % der ältesten Nachrichten und komprimiert sie rekursiv.
Für den KMU-Helpdesk bedeutet das: Ein Agent erinnert sich nach Wochen noch daran, welche Schritte mit einem Nutzer bereits durchgeführt wurden – ohne dass jemand manuell eine History übergeben muss.
Schritt 2: Verzeichnis und .env-Datei anlegen
Lege zunächst das Arbeitsverzeichnis und die Konfigurationsdatei an. Sensible Werte gehören nie als Klartextargumente in den Docker-Befehl.
mkdir -p ~/letta/data/pgdata ~/letta/data/letta ~/letta/backups
cd ~/lettaErzeuge ein sicheres Passwort und notiere es:
openssl rand -base64 32Erstelle die Datei ~/letta/.env:
SECURE=true
LETTA_SERVER_PASSWORD=DeinSicheresPasswortHier
# Wähle einen oder mehrere Provider:
OPENAI_API_KEY=sk-proj-...
# ANTHROPIC_API_KEY=sk-ant-...
# OLLAMA_BASE_URL=http://host.docker.internal:11434/v1Berechtigungen einschränken – die Datei enthält API-Keys:
chmod 600 ~/letta/.envSchritt 3: Docker Compose einrichten (empfohlener Weg)
Für den Dauerbetrieb ist Docker Compose dem manuellen docker run vorzuziehen: automatischer Neustart, Ressourcenlimits, strukturiertes Logging und Health-Check sind direkt integriert.
Erstelle ~/letta/docker-compose.yml:
version: "3.9"
services:
letta:
image: letta/letta:latest
ports:
- "127.0.0.1:8283:8283"
volumes:
- ./data/pgdata:/var/lib/postgresql/data
- ./data/letta:/root/.letta
env_file: .env
restart: unless-stopped
deploy:
resources:
limits:
cpus: "2.0"
memory: 3G
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8283/v1/health"]
interval: 30s
timeout: 10s
retries: 5
start_period: 90s
logging:
driver: json-file
options:
max-size: "10m"
max-file: "5"Container starten:
docker compose up -dLogs beobachten – der Erststart dauert 2–3 Minuten, weil Alembic automatisch ca. 42 Datenbanktabellen anlegt:
docker compose logs -f lettaVerifizieren: Warte, bis in den Logs keine Migrations-Ausgaben mehr erscheinen, dann:
curl http://127.0.0.1:8283/v1/healthErwartete Ausgabe: {"status":"ok"} – erst dann ist der Server vollständig gestartet. Connection refused in den ersten Minuten ist normales Verhalten, kein Fehler.
Schritt 4: Nginx als Reverse Proxy mit TLS einrichten
Port 8283 darf niemals direkt ins Internet geöffnet werden – der Server hat kein eingebautes TLS und keine Rate-Limits. Der einzig vertretbare Weg für Produktionsbetrieb ist ein Reverse Proxy mit HTTPS. Wer Caddy bevorzugt, findet die Grundlagen in der Anleitung Caddy als Reverse Proxy mit automatischem HTTPS. Hier der Weg mit Nginx und Certbot:
sudo apt install -y nginx certbot python3-certbot-nginx
sudo certbot --nginx -d letta.ihredomain.dePasse die Nginx-Konfiguration für /etc/nginx/sites-available/letta an:
server {
listen 443 ssl;
server_name letta.ihredomain.de;
client_max_body_size 25M;
proxy_read_timeout 600s;
proxy_send_timeout 600s;
limit_req_zone $binary_remote_addr zone=letta_api:10m rate=30r/m;
location / {
limit_req zone=letta_api burst=10;
proxy_pass http://127.0.0.1:8283;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
}
}Konfiguration aktivieren und Nginx neu laden:
sudo ln -s /etc/nginx/sites-available/letta /etc/nginx/sites-enabled/
sudo nginx -t && sudo systemctl reload nginxVerifizieren: curl https://letta.ihredomain.de/v1/health gibt {"status":"ok"} zurück und der Browser zeigt ein gültiges Zertifikat. Das proxy_read_timeout 600s ist wichtig – der Nginx-Standard von 60 Sekunden ist für längere Agenten-Antworten zu kurz.
Schritt 5: Lokale Modelle per Ollama einbinden
Wer keine Cloud-API nutzen möchte, kann Letta vollständig mit lokalen Modellen über Ollama betreiben. Die Anbindung unterscheidet sich je nach Betriebssystem des Hosts.
Ollama-Modell mit korrektem Tag und Quantisierung herunterladen – niemals ohne Tag:
# Korrekt (vollständiger Tag mit Quantisierung):
ollama pull llama3.2:3b-instruct-q5_K_M
# Embedding-Modell für Archival Memory:
ollama pull nomic-embed-textErgänze die .env entsprechend deiner Plattform:
macOS / Windows (Docker Desktop, host.docker.internal verfügbar):
OLLAMA_BASE_URL=http://host.docker.internal:11434/v1Linux (host.docker.internal ist im Standard-Bridge-Netzwerk nicht verfügbar):
# In docker-compose.yml network_mode ergänzen:
services:
letta:
network_mode: host
# ports: Zeile entfernen (bei host-Netzwerk nicht nötig)
# In .env:
OLLAMA_BASE_URL=http://localhost:11434/v1Wichtiger Hinweis zu Quantisierungen: Laut offizieller Letta-Dokumentation sollten nur Quantisierungen ab Q5 verwendet werden. Q4 und niedrigere Stufen beeinträchtigen die Qualität der Gedächtnis-Selbstverwaltungsfunktionen merklich, weil die dafür nötigen Funktionsaufrufe präzise generiert werden müssen. Modelle unter 7B Parametern können ebenfalls Schwierigkeiten mit den Memory-Tools haben. Eine ausführliche Modellübersicht bietet Ollama-Modelle 2026 richtig auswählen.
Schritt 6: Python-Client verbinden und ersten Agenten anlegen
Letta lässt sich per REST-API, Python-SDK oder über die ADE-Desktop-App steuern. Der schnellste Einstieg geht über den offiziellen Python-Client:
pip install letta-client
from letta_client import Letta
client = Letta(
base_url="https://letta.ihredomain.de",
token="DeinServerPasswort"
)
# Ersten Agenten anlegen
agent = client.agents.create(
name="helpdesk-agent-01",
model="openai/gpt-4o-mini", # oder ollama/llama3.2:3b-instruct-q5_K_M
embedding="openai/text-embedding-3-small"
)
print(f"Agent ID: {agent.id}")
# Nachricht senden
response = client.agents.messages.create(
agent_id=agent.id,
messages=[{"role": "user", "content": "Hallo, ich bin Marcel aus der IT-Abteilung."}]
)
print(response.messages[-1].content)Die ADE-Desktop-App (oder chat.letta.com) verbindet sich mit dem Self-Hosted-Server über die Domain-URL und das konfigurierte LETTA_SERVER_PASSWORD.
Verifizieren: docker compose ps zeigt letta mit Status healthy. Die Antwort des Agenten in der Python-Konsole enthält den übergebenen Namen im Core Memory – ein Zeichen, dass die Persistenzschicht korrekt arbeitet.
Schritt 7: Automatisches Datenbank-Backup einrichten
Alle Agenten, Gedächtnisblöcke und Gesprächsverläufe liegen in PostgreSQL. Vor jedem Image-Update muss ein Backup erstellt werden – Alembic-Migrationen sind nicht ohne weiteres rückwärtskompatibel.
Tägliches Backup per Cron (täglich 3:00 Uhr), alte Sicherungen werden nach 14 Tagen gelöscht:
crontab -e
0 3 * * * cd ~/letta && mkdir -p backups && \
docker compose exec -T letta pg_dump -U letta -d letta | \
gzip > backups/letta-$(date +\%Y\%m\%d).sql.gz && \
find backups/ -name "*.sql.gz" -mtime +14 -deleteWeitere Backup-Strategien (offsite, immutable) findest du in der Anleitung MySQL & PostgreSQL Backup automatisieren mit cron.
Schritt 8: Image aktualisieren
Für Produktionsumgebungen ist es empfehlenswert, statt latest eine feste Version zu pinnen (z. B. letta/letta:0.6.x), um unbeabsichtigte Breaking Changes durch Alembic-Migrationen zu vermeiden. Vor jedem Update:
# 1. Backup erstellen (siehe oben)
# 2. Neues Image ziehen und Container neu starten:
docker compose pull
docker compose up -d
docker compose logs -f lettaWarte erneut auf den Abschluss der Alembic-Migrationen im Log, bevor du den Dienst nutzt.
Systemanforderungen und Ressourcenverbrauch
| Szenario | RAM | CPU | GPU | Startgröße | Wachstum |
|---|---|---|---|---|---|
| Entwicklung / Test | 2 GB | 2 vCPU | Nicht nötig | ~800 MB | 50–200 MB/Monat/Agent |
| Produktion (mehrere Nutzer) | 4 GB | 4 vCPU | Nicht nötig | ~800 MB | abhängig von Nutzerzahl |
| Python-Server allein | ~500 MB | – | – | – | – |
| PostgreSQL/pgvector allein | ~300 MB | – | – | – | – |
Unterstützte LLM-Provider
| Provider | Umgebungsvariable | Embeddings | Hinweis |
|---|---|---|---|
| OpenAI | OPENAI_API_KEY | Ja | Vollständig unterstützt |
| Anthropic | ANTHROPIC_API_KEY | Nein | Externes Embedding-Modell zwingend |
| Ollama (lokal) | OLLAMA_BASE_URL | Ja (nomic-embed-text) | host.docker.internal auf macOS/Windows |
| LM Studio | OpenAI-kompatibler Endpunkt | Ja | Wie Ollama konfigurieren |
| Azure OpenAI | AZURE_OPENAI_API_KEY | Ja | Enterprise-Deployment |
| AWS Bedrock | AWS-Credentials | Modellabhängig | Enterprise-Deployment |
| OpenRouter | OPENROUTER_API_KEY | Nein | Routing-Dienst |
Troubleshooting / Typische Fehler
Container startet, aber /v1/health gibt Connection refused
Normales Verhalten beim Erststart. Alembic legt ~42 Tabellen an – das dauert auf einem 2-GB-VPS 2–3 Minuten. Einfach abwarten und Logs mit docker compose logs -f letta beobachten. Erst wenn die Migration abgeschlossen ist, antwortet der API-Server.
Ollama nicht erreichbar auf Linux
host.docker.internal existiert im Standard-Bridge-Netzwerk unter Linux nicht. Lösung: network_mode: host in der Compose-Datei setzen und OLLAMA_BASE_URL=http://localhost:11434/v1 verwenden. Die ports:-Zeile muss dabei entfernt werden.
Anthropic-Setup: Archival Memory funktioniert nicht
Anthropic liefert keine Embedding-Modelle. Ohne separates Embedding schlägt die Archival-Memory-Initialisierung still fehl. Abhilfe: entweder OPENAI_API_KEY zusätzlich setzen oder LETTA_DEFAULT_EMBEDDING_MODEL auf ein Ollama-Modell wie nomic-embed-text konfigurieren.
Volume-Mount vergessen
Ohne -v ./data/pgdata:/var/lib/postgresql/data legt PostgreSQL seine Daten im Container an. Nach jedem docker compose down oder Container-Neustart sind alle Agenten und Gedächtnisinhalte unwiederbringlich verloren. Volume-Mount in der Compose-Datei prüfen.
Nginx-Timeouts bei langen Antworten
Der Nginx-Standard-Timeout von 60 Sekunden reicht für längere Agenten-Antworten nicht aus. proxy_read_timeout und proxy_send_timeout müssen auf mindestens 600s gesetzt sein – sonst bricht Nginx die Verbindung mit HTTP 504 ab.
Ollama-Modell ohne Tag geladen
ollama pull llama3.2 (ohne Tag) führt zu undefiniertem Verhalten in Letta. Immer den vollständigen Tag mit Quantisierung angeben: ollama pull llama3.2:3b-instruct-q5_K_M. Quantisierungen unter Q5 beeinträchtigen die Qualität der Gedächtnisverwaltung.
Image-Tag latest in Produktion
Automatische Updates können Breaking Changes in Alembic-Migrationen einschleppen. Produktionsumgebungen sollten eine gepinnte Version verwenden, z. B. letta/letta:0.6.x. Vor jedem Update Backup erstellen.
Häufige Fragen
Brauche ich eine GPU für Letta on-premise?
Nein. Der Letta-Server selbst benötigt keine GPU – er delegiert die LLM-Inferenz an externe oder lokale Provider. Eine GPU wird nur dann gebraucht, wenn du Ollama lokal mit einem großen Modell betreibst und dabei GPU-Beschleunigung nutzen möchtest. Bei rein cloudbasierten Providern (OpenAI, Anthropic) reicht ein Standard-VPS vollständig aus. Mehr zur GPU-Auswahl für lokale KI findest du in der Anleitung GPU für lokale KI auswählen: VRAM, RTX-Generationen und Budget-Empfehlungen 2026.
Was passiert mit den Gedächtnisinhalten bei einem Container-Neustart?
Alle Daten liegen in PostgreSQL, das über das Host-Volume (./data/pgdata) persistent gespeichert wird. Solange das Volume erhalten bleibt, bleiben alle Agenten, Gedächtnisblöcke und Gesprächsverläufe erhalten – unabhängig davon, wie oft der Container neu gestartet wird.
Kann ich mehrere Agenten mit gemeinsamem Gedächtnis betreiben?
Ja. Letta unterstützt sogenannte Shared Memory Blocks, auf die mehrere Agenten lesend und schreibend zugreifen können. Das ermöglicht beispielsweise eine gemeinsame Firmen-Wissensbasis für alle Helpdesk-Agenten: Jeder Agent kann neue Erkenntnisse in den gemeinsamen Block schreiben und von den Einträgen anderer Agenten profitieren.
Wie verbinde ich die ADE mit meinem Self-Hosted-Server?
In der ADE-Desktop-App oder unter chat.letta.com die Server-URL auf die eigene Domain (https://letta.ihredomain.de) und als Token das konfigurierte LETTA_SERVER_PASSWORD setzen. Ab diesem Moment werden alle Agenten über den eigenen Server verwaltet.
Ist das Docker-Image noch aktuell und gepflegt?
Das Image wird weiterhin auf Docker Hub gepflegt und ist technisch voll funktionsfähig. Die offizielle Letta-Dokumentation weist darauf hin, dass zunehmend der "Letta Code local mode" als bevorzugter lokaler Betriebsmodus beworben wird. Für On-Premise-Serverdeployments im KMU-Umfeld bleibt das Docker-Image der empfohlene und dokumentierte Weg.
Welche lokalen Modelle eignen sich am besten?
Laut offizieller Empfehlung Modelle mit mindestens Q5-Quantisierung verwenden und dabei mindestens 7B Parameter einplanen. Kleinere Modelle können Schwierigkeiten haben, die Funktionsaufrufe für die Gedächtnisverwaltung zuverlässig zu generieren. Gute Einstiegsoptionen: llama3.2:3b-instruct-q5_K_M (für sehr schwache Hardware), mistral:7b-instruct-q5_K_M (ausgewogene Qualität).
Fazit
Letta schließt eine echte Lücke: Wer KI-Agenten produktiv für Helpdesk, Wissensverwaltung oder Automatisierung einsetzen möchte, braucht Persistenz – und genau das liefert Letta mit seinem selbstverwalteten Drei-Stufen-Gedächtnis. Der Docker-Einzelcontainer macht den Einstieg niedrigschwellig: ein Volume, eine .env-Datei, ein docker compose up. Für den Produktionsbetrieb sind Nginx mit TLS, gepinnte Image-Versionen und ein tägliches pg_dump-Backup die entscheidenden Bausteine. Die wichtigsten Fallstricke – Volume-Mount vergessen, Anthropic ohne Embedding-Modell, Ollama auf Linux ohne host-Netzwerk – lassen sich mit den Hinweisen in dieser Anleitung von Anfang an vermeiden. Ob du OpenAI, Anthropic oder vollständig lokale Modelle per Ollama einsetzt: Letta abstrahiert die Provider-Ebene sauber und hält die Agentendaten on-premise.
Weiterführende Anleitungen und Quellen
- Docker und Docker Compose auf Linux installieren (Ubuntu/Debian)
- Ollama und Open WebUI mit Docker: eigenes lokales KI-Sprachmodell ohne Cloud betreiben
- MySQL & PostgreSQL Backup automatisieren mit cron
- Caddy als Reverse Proxy einrichten: Anleitung mit automatischem HTTPS
- Ollama-Modelle 2026 richtig auswählen: VRAM, Quantisierung und Modellvergleich für KMU
- GPU für lokale KI auswählen: VRAM, RTX-Generationen und Budget-Empfehlungen 2026
- Letta Docs – Docker Deployment (offiziell)
- Docker Hub – letta/letta Image
- Letta Docs – Ollama Provider


