AnythingLLM installieren (Docker): Lokale KI-Zentrale mit RAG-Workspaces und Ollama
AnythingLLM installieren per Docker: Schritt-für-Schritt zur lokalen KI-Zentrale mit RAG-Workspaces, Ollama als LLM-Backend und Multi-User-Verwaltung - vollständig auf deinem eigenen Server, ohne Cloud.
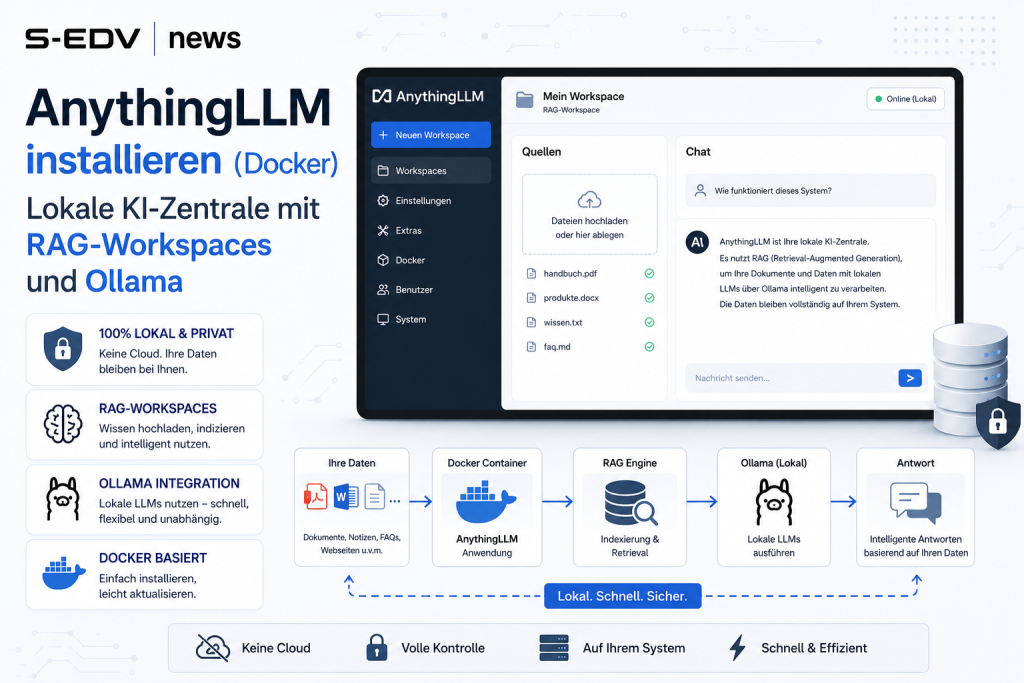
AnythingLLM installieren heißt, dir eine eigene, lokale KI-Zentrale aufzubauen, in der du Dokumente per RAG durchsuchbar machst, mit lokalen Sprachmodellen chattest und mehrere Nutzer mit Rollen verwaltest - alles auf deinem eigenen Server, ohne dass Daten an einen Cloud-Anbieter abfliessen. Diese Anleitung zeigt dir den kompletten Weg per Docker: vom Container über die Anbindung an Ollama als LLM-Backend bis hin zu RAG-Workspaces für verschiedene Use-Cases und der Multi-User-Verwaltung. Die Anleitung richtet sich an IT-affine Nutzer, Admins und die Selfhosting-Szene, die eine zentrale Oberfläche für ihre lokale KI suchen.
Was ist AnythingLLM und warum lohnt es sich?
AnythingLLM von Mintplex Labs ist eine Open-Source-Plattform, die mehrere Bausteine einer lokalen KI-Lösung unter einer Oberfläche bündelt: eine Chat-UI, ein Dokumenten-RAG-System (Retrieval Augmented Generation), eine Vektordatenbank und eine Nutzerverwaltung. Du lädst Dokumente hoch, AnythingLLM zerlegt sie in Abschnitte (Chunks), erzeugt daraus Embeddings und legt sie in einer Vektordatenbank ab. Stellst du dann eine Frage, sucht das System die passenden Textstellen heraus und gibt sie zusammen mit deiner Frage an das Sprachmodell - so antwortet die KI auf Basis deiner eigenen Dokumente statt nur aus ihrem Trainingswissen.
Der zentrale Vorteil: Im Zusammenspiel mit Ollama läuft die gesamte Verarbeitung lokal. Weder deine Dokumente noch deine Prompts verlassen den Server. AnythingLLM organisiert das Ganze über Workspaces - jeder Workspace ist ein eigener, abgeschotteter RAG-Kontext mit eigenen Dokumenten, eigenem Systemprompt und eigenen Einstellungen. So trennst du etwa "Interne IT-Doku", "Vertragsrecht" und "Projekt X" sauber voneinander, ohne dass Inhalte vermischt werden.
Wann ist AnythingLLM die richtige Wahl?
AnythingLLM ist ideal, wenn du nicht nur ein Chat-Frontend brauchst, sondern eine echte Wissensplattform mit Dokumentenbasis und mehreren Nutzern. Geht es dir dagegen nur um einen schlanken Chat mit lokalen Modellen, ist eine Kombination aus Ollama und Open WebUI oft die einfachere Wahl - siehe dazu unsere Anleitung weiter unten.
Voraussetzungen
- Ein Linux-Server, eine VM oder ein Homeserver mit Docker und Docker Compose (alternativ Windows/macOS mit Docker Desktop).
- Mindestens 4 GB RAM frei für AnythingLLM selbst; für Ollama-Modelle zusätzlich je nach Modellgröße 8 GB RAM aufwärts (eine GPU beschleunigt deutlich, ist aber kein Muss).
- Eine laufende Ollama-Instanz auf
localhost:11434mit mindestens einem geladenen Chat-Modell (z. B.llama3.1) und optional einem Embedding-Modell (z. B.nomic-embed-text). - Rund 5 GB freier Speicherplatz für den Container plus Platz für deine Dokumente und die Vektordatenbank.
- Grundkenntnisse in der Shell und im Umgang mit Docker-Volumes.
Schritt 1: Docker prüfen und Verzeichnisstruktur anlegen
Stelle zuerst sicher, dass Docker läuft, und lege einen Ordner für die persistenten Daten an. Falls Docker noch nicht installiert ist, folge zuerst unserer Docker-Grundinstallation (Link am Ende des Artikels).
- Docker-Version prüfen:
docker --version
docker compose version- Projektverzeichnis und den Daten-Unterordner anlegen:
mkdir -p ~/anythingllm/storage
cd ~/anythingllmDer Ordner storage nimmt später die interne Datenbank, die Vektorindizes, die hochgeladenen Dokumente und die Konfiguration auf. Damit der Container in dieses Volume schreiben darf, legen wir die Datenbankdatei an und setzen die Schreibrechte.
touch storage/anythingllm.db
chmod -R 777 ~/anythingllm/storageSchritt 2: docker-compose.yml mit Volume und Ollama-Anbindung erstellen
Erstelle im Projektordner eine docker-compose.yml. Sie definiert den Container, den Port 3001, das Storage-Volume und reicht über host.docker.internal den Zugriff auf die auf dem Host laufende Ollama-Instanz durch.
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
ports:
- "3001:3001"
environment:
- STORAGE_DIR=/app/server/storage
- JWT_SECRET=bitte-hier-einen-langen-zufallswert-eintragen
volumes:
- ./storage:/app/server/storage
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stoppedWichtig: Ersetze den Wert von JWT_SECRET durch einen langen Zufallswert (z. B. mit openssl rand -hex 32 erzeugt). Das Volume ./storage hält sowohl die Datenbank als auch die hochgeladenen Dokumente und die Vektorindizes persistent - so überleben deine Daten jeden Container-Neustart und jedes Update.
Hinweis zu host.docker.internal unter Linux
Der Eintrag unter extra_hosts sorgt dafür, dass der Container den Host unter dem Namen host.docker.internal erreicht - das brauchst du gleich für die Ollama-URL. Unter Docker Desktop (Windows/macOS) ist dieser Name automatisch verfügbar.
Schritt 3: Container starten und Erstkonfiguration aufrufen
- Container im Hintergrund starten:
docker compose up -d- Logs beobachten, bis der Server bereit ist:
docker compose logs -f anythingllm- Sobald der Server läuft, öffne im Browser die Oberfläche:
http://SERVER-IP:3001Beim ersten Aufruf führt dich ein Einrichtungsassistent durch die Grundkonfiguration. Hier wählst du gleich deinen LLM-Provider, den Embedding-Anbieter und die Vektordatenbank. Die Vektordatenbank (LanceDB) ist standardmäßig integriert und braucht keinen separaten Container.
Schritt 4: Ollama als LLM-Provider verbinden
Jetzt bindest du dein lokales Sprachmodell an. Stelle sicher, dass Ollama läuft und auf allen Schnittstellen erreichbar ist, damit der Container es über host.docker.internal ansprechen kann.
- Auf dem Host prüfen, ob Ollama antwortet und ein Modell geladen ist:
curl http://localhost:11434/api/tags
ollama pull llama3.1- In AnythingLLM unter Settings → AI Providers → LLM als Provider Ollama wählen.
- Als Ollama Base URL eintragen:
http://host.docker.internal:11434- Das gewünschte Chat-Modell (z. B.
llama3.1) aus der Liste auswählen und speichern.
Damit Ollama auch aus dem Container erreichbar ist, muss es nicht nur auf 127.0.0.1, sondern auf 0.0.0.0 lauschen. Setze dazu auf dem Host die Umgebungsvariable und starte den Ollama-Dienst neu:
OLLAMA_HOST=0.0.0.0:11434Schritt 5: Embeddings konfigurieren
Für das RAG braucht AnythingLLM ein Embedding-Modell, das deine Dokumente in Vektoren umwandelt. Du hast zwei Optionen:
- Lokal über Ollama: Lade ein Embedding-Modell und wähle es als Embedding-Provider. Das hält auch diesen Schritt komplett lokal.
ollama pull nomic-embed-text- Eingebauter Embedder: AnythingLLM bringt von Haus aus einen lokalen Embedder mit, der ohne Zusatzmodell direkt funktioniert. Für kleinere Setups reicht das völlig.
Stelle den gewünschten Anbieter unter Settings → AI Providers → Embedder ein. Wer maximale Datenhoheit will, nutzt den lokalen Ollama-Embedder oder den eingebauten Embedder - eine externe API ist hier nicht nötig.
Schritt 6: Workspace anlegen und RAG-Dokumente hochladen
Workspaces sind das Herz von AnythingLLM. Jeder Workspace ist ein eigener RAG-Kontext mit eigenen Dokumenten und eigenem Systemprompt.
- In der Oberfläche links auf New Workspace klicken und einen sprechenden Namen vergeben (z. B. "IT-Dokumentation").
- Den Workspace öffnen und über das Upload-Symbol Dokumente hinzufügen. Unterstützt werden unter anderem PDF, TXT, DOCX und CSV; AnythingLLM indexiert sie automatisch.
- Die hochgeladenen Dateien im Dialog mit Move to Workspace aktivieren und mit Save and Embed einbetten. Jetzt werden die Dokumente in Chunks zerlegt und als Embeddings in der Vektordatenbank abgelegt.
- Optional einen Systemprompt pro Workspace setzen (z. B. "Antworte ausschließlich auf Basis der bereitgestellten Dokumente").
Lege für jeden Use-Case einen eigenen Workspace an. So bleibt der Kontext sauber getrennt und die Antworten präzise, weil das RAG nur die Dokumente des jeweiligen Workspace durchsucht.
Schritt 7: Multi-User und Rollen aktivieren
AnythingLLM bringt ein integriertes Multi-User-System mit Rollen mit. Standardmäßig läuft die Instanz im Single-User-Modus - für den Team-Einsatz aktivierst du den Mehrbenutzermodus.
- Unter Settings → Security → Multi-User Mode den Mehrbenutzermodus aktivieren.
- Ein Admin-Konto mit Benutzername und Passwort anlegen - dieses Konto verwaltet künftig alle Nutzer.
- Unter Settings → Users weitere Nutzer hinzufügen und ihnen Rollen zuweisen: Admin (volle Verwaltung), Manager (Workspaces und Nutzer eingeschränkt) oder Default (nur zugewiesene Workspaces nutzen).
- Jedem Nutzer gezielt die erlaubten Workspaces zuweisen, damit niemand Dokumente sieht, die ihn nichts angehen.
Schritt 8: Verifikation und erster Test
Prüfe nun, ob die gesamte Kette funktioniert - vom Modell über die Embeddings bis zum RAG.
- Im Workspace eine Frage stellen, deren Antwort nur in den hochgeladenen Dokumenten steht.
- Prüfen, ob die Antwort die Inhalte korrekt wiedergibt und ob unter der Antwort die zitierten Quellen (Citations) angezeigt werden.
- Container-Status und Health prüfen:
docker compose ps
curl -I http://localhost:3001Erscheinen die Citations und passt die Antwort zum Dokument, arbeitet das RAG korrekt. Bleibt die Antwort generisch oder ohne Quellen, kontrolliere, ob die Dokumente wirklich eingebettet (embedded) wurden und ein Embedding-Modell konfiguriert ist.
Updates und Wartung
Dank des Storage-Volumes sind Updates unkompliziert. Du ziehst das neue Image und startest den Container neu - deine Daten bleiben im Volume erhalten.
docker compose pull
docker compose up -d
docker image prune -fNach größeren Versionssprüngen lohnt ein Blick in die offiziellen Release-Notes, da sich gelegentlich Einstellungen oder das Datenformat ändern. Prüfe nach jedem Update kurz, ob deine Workspaces und die Provider-Verbindung zu Ollama noch korrekt eingestellt sind.
Backup
Das komplette Backup ist denkbar einfach: Sichere regelmäßig den gesamten storage-Ordner, denn er enthält die Datenbank, die Dokumente und die Vektorindizes. Stoppe den Container kurz, um einen konsistenten Stand zu bekommen, und packe das Verzeichnis ein.
docker compose stop
tar czf anythingllm-backup-$(date +%F).tar.gz storage/
docker compose startBewahre die Sicherung auf einem getrennten Datenträger oder einem zweiten Server auf. Zum Wiederherstellen entpackst du das Archiv einfach an die alte Stelle und startest den Container neu.
Troubleshooting
- Ollama wird nicht erreicht: Prüfe, ob Ollama mit
OLLAMA_HOST=0.0.0.0:11434läuft und der Eintraghost.docker.internal:host-gatewayunterextra_hostsgesetzt ist. Teste die Verbindung notfalls aus dem Container heraus mitdocker exec -it anythingllm curl http://host.docker.internal:11434/api/tags. - Keine Antworten aus Dokumenten: Vergewissere dich, dass die Dateien mit Save and Embed tatsächlich eingebettet wurden und ein Embedding-Provider konfiguriert ist.
- Permission denied im Storage: Setze die Rechte mit
chmod -R 777 storageoder passe den Eigentümer an die UID des Containers an. - Port 3001 belegt: Ändere das Port-Mapping in der Compose-Datei, z. B. auf
"3002:3001". - Modell antwortet sehr langsam: Das liegt meist an fehlender GPU oder einem zu großen Modell - wähle ein kleineres Ollama-Modell oder nutze GPU-Beschleunigung für Ollama.
Häufige Fragen
Läuft AnythingLLM komplett lokal und offline?
Ja. In Kombination mit Ollama als LLM-Provider und einem lokalen Embedder verarbeitet AnythingLLM Prompts, Dokumente und Embeddings vollständig auf deinem Server. Es ist keine Cloud-API nötig, sodass keine Daten nach außen gelangen.
Was ist der Unterschied zwischen einem Workspace und einem Chat?
Ein Workspace ist ein abgeschotteter RAG-Kontext mit eigenen Dokumenten, eigenem Systemprompt und eigenen Einstellungen. Ein Chat ist ein Gesprächsverlauf innerhalb eines Workspace. So kannst du verschiedene Themengebiete sauber trennen, ohne dass sich die Dokumentenbasis vermischt.
Welche Dateiformate kann AnythingLLM für RAG verarbeiten?
AnythingLLM indexiert unter anderem PDF, TXT, DOCX und CSV automatisch. Daneben lassen sich auch Webseiten und weitere Quellen über die integrierten Connectoren einlesen und den Workspaces zuordnen.
Brauche ich zwingend eine GPU?
Nein. AnythingLLM selbst läuft problemlos ohne GPU. Die Geschwindigkeit hängt vor allem an Ollama: Eine GPU beschleunigt die Antwortzeiten der Sprachmodelle deutlich, für kleinere Modelle reicht aber auch eine reine CPU-Ausführung.
Kann ich AnythingLLM mit mehreren Nutzern betreiben?
Ja. Über den integrierten Multi-User-Modus legst du Nutzer mit den Rollen Admin, Manager und Default an und weist ihnen gezielt Workspaces zu. Damit eignet sich die Plattform auch für Teams mit getrennten Zugriffsrechten.
Fazit
Mit Docker, einem Storage-Volume und einer Ollama-Anbindung hast du AnythingLLM installiert und damit eine vollwertige, lokale KI-Zentrale aufgebaut. Du chattest mit lokalen Modellen, machst eigene Dokumente per RAG durchsuchbar, organisierst alles in dedizierten Workspaces und verwaltest mehrere Nutzer mit Rollen - ohne dass Daten deinen Server verlassen. Die Architektur bleibt durch das saubere Volume-Konzept wartungsarm: Updates und Backups sind in wenigen Befehlen erledigt.
Weiterführende Anleitungen
Wenn du das LLM-Backend noch nicht stehen hast, richte zuerst Ollama mit einer schlanken Chat-Oberfläche ein - in unserer Anleitung Ollama mit Open WebUI per Docker für lokale LLMs zeigen wir den kompletten Weg. Fehlt dir die Container-Basis, hilft dir unsere Docker-Installation Schritt für Schritt. Weitere Selfhosting-Anleitungen findest du in der Kategorie Docker.
Quellen
Offizielle Dokumentation und Quellcode: AnythingLLM Documentation, Mintplex-Labs/anything-llm auf GitHub sowie die offizielle Docker-Image-Seite und die Ollama-Projektseite.


