Whisper lokal mit GUI installieren: Offline-Spracherkennung auf Deutsch ohne Cloud
Whisper lokal installieren mit GUI: So transkribierst du Audio offline auf Deutsch ohne Cloud, ohne Python-Kenntnisse und ohne laufende Kosten. Schritt für Schritt für Windows.
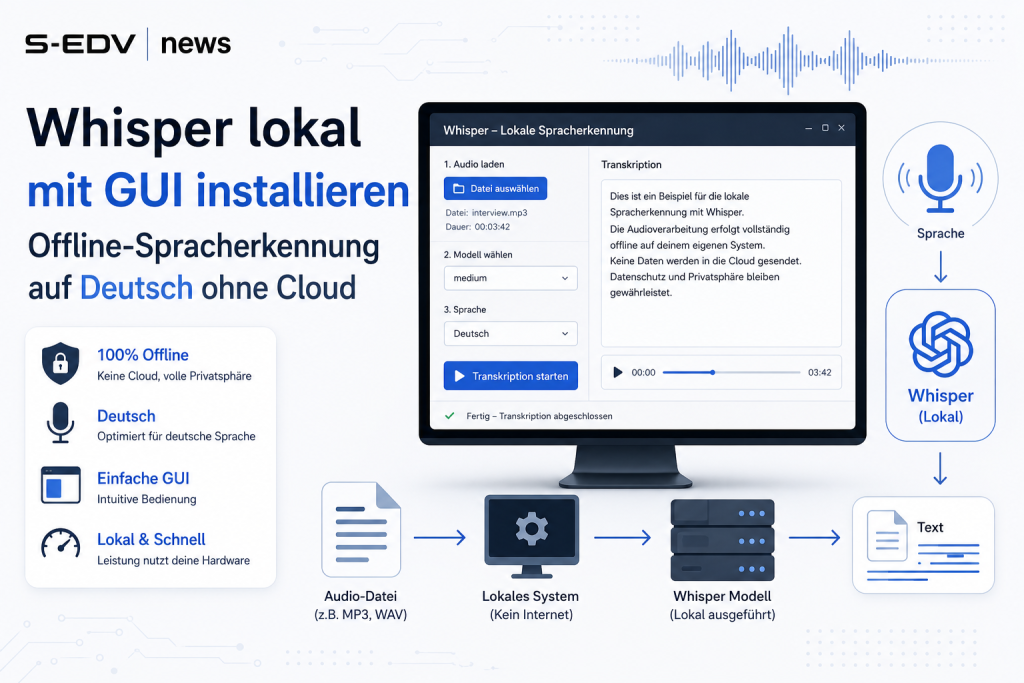
Wenn du Audio oder Video offline auf Deutsch transkribieren willst, ohne deine Aufnahmen in eine Cloud hochzuladen, ist Whisper lokal mit GUI die einfachste Lösung. In dieser Anleitung zeige ich dir, wie du Whisper lokal installierst und über eine grafische Oberfläche bedienst - komplett ohne Python-Kenntnisse, ohne Kommandozeilen-Magie und ohne monatliche Kosten. Das Ergebnis: eine vollwertige Spracherkennung lokal auf deinem Windows-Rechner, die aus Sprachmemos, Interviews, Meetings oder Videos saubere Textdateien, SRT-Untertitel oder VTT-Dateien macht. Diese Anleitung richtet sich an Einsteiger, Content-Ersteller, Journalisten, Studierende und alle, die Datenschutz ernst nehmen und ihre Audio-zu-Text-Verarbeitung im eigenen Haus behalten wollen.
Was ist Whisper und warum lokal statt Cloud?
Whisper ist ein von OpenAI entwickeltes Open-Source-Modell zur automatischen Spracherkennung (ASR). Es wandelt gesprochene Sprache in Text um und beherrscht dabei zahlreiche Sprachen - inklusive sehr gutem Deutsch. Anders als die OpenAI-API läuft Whisper vollständig auf deiner eigenen Hardware. Das bedeutet: deine Aufnahmen verlassen niemals deinen Rechner.
In der Praxis nutzt man heute selten das originale Python-Whisper direkt. Stattdessen hat sich Faster-Whisper durchgesetzt - eine Reimplementierung, die auf der CTranslate2-Engine basiert und deutlich schneller bei geringerem Speicherverbrauch läuft. Der Entwickler Purfview stellt davon eine fertige Whisper Standalone-Executable für Windows bereit: ein einzelnes Programm, das ohne Python-Installation funktioniert. Kombiniert mit einem grafischen Wrapper bekommst du eine echte Audio zu Text offline-Lösung mit Klick-Bedienung.
Die Vorteile gegenüber Cloud-Diensten:
- Datenschutz: Vertrauliche Interviews, Patientengespräche oder interne Meetings bleiben lokal - DSGVO-konform ohne Auftragsverarbeitung.
- Keine laufenden Kosten: Du zahlst nichts pro Minute, egal wie viel du transkribierst.
- Offline-Fähigkeit: Funktioniert auch ohne Internet, etwa im Zug oder im abgeschotteten Netz.
- Volle Kontrolle: Du wählst Modellgröße, Sprache und Ausgabeformat selbst.
Voraussetzungen
- Windows 10 oder 11 (64-Bit). Die Standalone-Builds gibt es auch für Linux, diese Anleitung fokussiert Windows.
- Mindestens 8 GB RAM, besser 16 GB - das
medium-Modell braucht spürbar Arbeitsspeicher. - Freier Speicherplatz: rund 150 MB bis 3 GB je nach Modell. Plane lieber 10 GB ein, falls du mehrere Modelle testen willst.
- Eine moderne CPU. Eine NVIDIA-GPU mit CUDA ist optional, beschleunigt aber enorm.
- Eine Audio- oder Videodatei zum Testen (MP3, WAV, M4A, MP4 etc.).
- Ein entpacktes 7-Zip oder den Windows-Explorer zum Auspacken der Archive.
Du brauchst keine Python-Installation und keinen Account. Die Standalone-Variante bringt alles Nötige mit.
Schritt 1: Faster-Whisper Standalone herunterladen
- Öffne die Releases-Seite des Projekts
Purfview/whisper-standalone-winauf GitHub. - Lade unter dem aktuellen Release das Archiv
Faster-Whisper-XXLfür Windows herunter. Die XXL-Variante enthält zusätzliche Features wie integrierte Sprachtrennung und mehr Ausgabeformate. - Entpacke das ZIP-Archiv an einen festen Ort, zum Beispiel
C:\Whisper. Vermeide Pfade mit Sonderzeichen oder OneDrive-Synchronisation, das spart später Ärger.
Nach dem Entpacken findest du im Ordner die ausführbare Datei faster-whisper-xxl.exe sowie mehrere Hilfsbibliotheken. Du kannst das Programm bereits jetzt über die Kommandozeile testen:
cd C:\Whisper\Faster-Whisper-XXL
.\faster-whisper-xxl.exe --helpWenn eine Hilfe-Ausgabe mit allen Parametern erscheint, ist die Executable lauffaehig. Die GUI bauen wir im nächsten Schritt darum herum - die eigentliche Arbeit erledigt aber genau diese Datei.
Schritt 2: GUI-Wrapper einrichten
Die Standalone-Executable ist ein Kommandozeilen-Tool. Damit du ohne Befehle arbeiten kannst, gibt es zwei bequeme Wege.
Variante A: Mitgelieferte Drag-and-Drop-Skripte
Die Faster-Whisper-XXL-Pakete enthalten oft fertige Batch-Skripte (zum Beispiel _xxl.bat oder ähnliche Helfer). Du ziehst eine Audiodatei einfach auf das Skript, und die Transkription startet mit voreingestellten Parametern. Das ist die schnellste Variante ganz ohne Zusatzsoftware.
Variante B: Grafischer Wrapper whisper-gui
Für eine richtige Oberfläche mit Auswahlfeldern nutzt du einen GUI-Wrapper wie whisper-gui (auf GitHub als reines Frontend verfügbar). Solche Wrapper zeigen dir Eingabefelder für Datei, Modell, Sprache und Ausgabeformat und rufen im Hintergrund die Executable auf. Lade den Wrapper herunter, entpacke ihn und verweise in den Einstellungen auf den Pfad deiner faster-whisper-xxl.exe.
Falls du einen eigenen Mini-Wrapper als Batch-Datei bevorzugst, reicht dieser Inhalt, den du als transkribieren.bat in den Whisper-Ordner legst:
@echo off
REM Datei per Drag-and-Drop auf diese .bat ziehen
"C:\Whisper\Faster-Whisper-XXL\faster-whisper-xxl.exe" %1 --language German --model medium --output_format srt --output_dir source
pauseDamit ziehst du jede Audiodatei auf die Batch-Datei und erhältst eine deutsche SRT-Datei im selben Ordner. Das ist faktisch schon eine funktionierende GUI-Bedienung per Maus.
Schritt 3: Das richtige deutsche Modell wählen
Die Modellgröße entscheidet über Qualität, Geschwindigkeit und Speicherbedarf. Für Faster-Whisper deutsch ist die Wahl besonders wichtig, weil kleine Modelle bei deutscher Grammatik und Eigennamen schnell schwächeln. Diese Übersicht hilft bei der Entscheidung:
| Modell | Größe (ca.) | Deutsch-Qualität | Empfehlung |
|---|---|---|---|
tiny | ~75 MB | schwach | nur für schnelle Tests |
base | ~145 MB | mäßig | einfache, klare Aufnahmen |
small | ~480 MB | ordentlich | Kompromiss bei schwacher Hardware |
medium | ~1,5 GB | gut | Empfehlung für Deutsch |
large-v3 | ~3,1 GB | sehr gut | beste Qualität, GPU sinnvoll |
Faustregel: Nimm für brauchbares Deutsch mindestens medium. Wenn deine Hardware mitmacht und du maximale Genauigkeit brauchst, ist large-v3 die Spitzenwahl. Das Modell wird beim ersten Lauf automatisch heruntergeladen und lokal zwischengespeichert - danach läuft alles komplett offline.
Schritt 4: Erste Transkription starten
Jetzt transkribierst du deine erste Datei. Über den GUI-Wrapper wählst du Datei, Sprache German, Modell medium und Ausgabeformat srt oder txt aus und klickst auf Start. Wer lieber die Kommandozeile nutzt, verwendet diesen Befehl:
.\faster-whisper-xxl.exe "C:\Aufnahmen\interview.mp3" --language German --model medium --output_format srt --output_dir "C:\Aufnahmen"Die wichtigsten Parameter im Klartext:
--language Germanerzwingt Deutsch und verhindert, dass Whisper die Sprache falsch errät.--model mediumwählt die Modellgröße.--output_formatakzeptiert unter anderemsrt,txt,vttoderjson.--output_dirlegt den Zielordner fest.
Die Geschwindigkeit ist stark hardwareabhängig: Auf einer CPU rechnet das medium-Modell grob mit 10 bis 30 Sekunden pro Minute Audio, eine starke GPU schafft 2 bis 5 Sekunden pro Minute. Eine Stunde Interview kann auf der CPU also durchaus 20 bis 30 Minuten dauern - plane das ein.
Schritt 5: Ergebnis prüfen und erster Test
- Öffne den Zielordner. Dort liegt nun eine Datei wie
interview.srtoderinterview.txt. - Öffne die
.txtin einem Editor und lies die ersten Absätze. Stimmen Eigennamen, Fachbegriffe und Satzzeichen einigermassen, war die Modellwahl richtig. - Bei einer
.srtkannst du die Datei direkt als Untertitel in einem Videoplayer wie VLC laden, um Zeitstempel und Synchronität zu prüfen.
Ist die Qualität zu schwach, hebe das Modell eine Stufe an (etwa von small auf medium oder von medium auf large-v3). Sind Wortgrenzen unsauber, hilft oft eine bessere Audioqualität der Quelldatei mehr als ein größeres Modell.
Schritt 6: GPU-Beschleunigung aktivieren (optional)
Wenn du eine NVIDIA-Grafikkarte besitzt, beschleunigt CUDA die Transkription massiv. Die Faster-Whisper-XXL-Builds bringen die nötigen CUDA-Bibliotheken in der Regel mit, sodass keine separate Installation nötig ist. Aktiviere die GPU über den Geräte-Parameter:
.\faster-whisper-xxl.exe "C:\Aufnahmen\interview.mp3" --language German --model large-v3 --device cuda --output_format srtMit --device cuda läuft die Berechnung auf der GPU. Erscheint eine Fehlermeldung zur CUDA-Bibliothek, fehlt meist der passende NVIDIA-Treiber - aktualisiere ihn über GeForce Experience oder die NVIDIA-Website. Ohne GPU lässt du den Parameter einfach weg, dann rechnet die CPU.
Updates und Wartung
Whisper Standalone hat keinen Auto-Updater. Prüfe alle paar Monate die GitHub-Releases von Purfview/whisper-standalone-win auf eine neue Version. Ein Update funktioniert denkbar einfach: neues Archiv herunterladen, in einen frischen Ordner entpacken und deine Skripte auf den neuen Pfad anpassen. Die heruntergeladenen Modelle musst du dabei nicht neu laden, wenn du den Modell-Cache-Ordner übernimmst.
Backup-Hinweis
Die heruntergeladenen Modelldateien sind mehrere hundert Megabyte bis einige Gigabyte groß. Sichere den Modell-Cache-Ordner mit, wenn du ein Offline-Backup deiner Arbeitsumgebung anlegst - dann musst du nach einem Neuaufsetzen nicht erneut alle Modelle ziehen. Wichtiger noch: Sichere deine Originalaufnahmen und fertigen Transkripte regelmäßig, denn die Quelldateien lassen sich nicht wiederherstellen. Eine einfache Kopie auf ein NAS oder eine externe Platte genügt.
Troubleshooting
- Programm startet nicht / DLL fehlt: Installiere das aktuelle Microsoft Visual C++ Redistributable (x64). Es fehlt auf frischen Windows-Installationen häufig.
- Falsche Sprache erkannt: Setze immer explizit
--language German, statt Whisper die Sprache raten zu lassen. - Sehr langsam: Ein kleineres Modell wählen, oder eine NVIDIA-GPU mit
--device cudanutzen. Auf reiner CPU istlarge-v3oft zäh. - Out-of-Memory: Bei zu wenig RAM oder VRAM eine Modellstufe kleiner wählen (etwa
mediumstattlarge-v3). - Halluzinierte Wiederholungen in Stille: Die Stimmaktivitätserkennung (VAD) ist bei den XXL-Builds bereits standardmäßig aktiv und filtert Stille heraus - bleibt das Problem, hilft eine sauberere Quelldatei oder das Beibehalten der VAD-Voreinstellung.
- Pfad mit Leerzeichen schlägt fehl: Setze Dateipfade immer in doppelte Anführungszeichen.
Häufige Fragen
Brauche ich Python, um Whisper lokal zu nutzen?
Nein. Die Faster-Whisper Standalone von Purfview ist eine einzelne Executable, die ohne Python-Installation läuft. In Kombination mit einem GUI-Wrapper oder einer Batch-Datei bedienst du alles per Maus - ganz ohne Programmierkenntnisse.
Welches Whisper-Modell ist am besten für deutsche Transkription?
Für brauchbares Deutsch solltest du mindestens das medium-Modell nutzen. Es liefert eine gute Balance aus Qualität und Geschwindigkeit. Wer maximale Genauigkeit und idealerweise eine GPU hat, nimmt large-v3. Die kleinen Modelle tiny und base eignen sich nur für schnelle Tests.
Funktioniert Whisper wirklich komplett offline?
Ja. Lediglich beim ersten Lauf wird das gewählte Modell einmalig heruntergeladen. Danach arbeitet die Spracherkennung vollständig lokal, ohne Internetverbindung und ohne dass Audiodaten deinen Rechner verlassen.
Wie lange dauert eine Transkription?
Das hängt stark von der Hardware ab. Auf einer CPU rechnet das medium-Modell etwa 10 bis 30 Sekunden pro Minute Audio, eine starke NVIDIA-GPU schafft 2 bis 5 Sekunden pro Minute. Eine Stunde Audio kann auf reiner CPU also durchaus 20 bis 30 Minuten benötigen.
Welche Ausgabeformate unterstützt Whisper?
Du kannst unter anderem reinen Text (txt), Untertitel (srt und vtt) sowie strukturierte Daten als json erzeugen. SRT und VTT eignen sich für Videountertitel, TXT für die Weiterverarbeitung in einem Textprogramm.
Fazit
Mit der Faster-Whisper Standalone und einem GUI-Wrapper hast du eine vollwertige, kostenlose und datenschutzfreundliche Spracherkennung lokal auf deinem Windows-Rechner. Du transkribierst Interviews, Meetings und Videos offline auf Deutsch, wählst die passende Modellgröße selbst und bekommst saubere TXT-, SRT- oder VTT-Dateien - ohne Cloud, ohne Account und ohne laufende Kosten. Für den Einstieg reicht das medium-Modell, für Profi-Qualität greifst du zu large-v3 mit GPU-Beschleunigung. Damit hast du eine zuverlässige Audio zu Text offline-Lösung, die du jederzeit erweitern kannst.
Weiterführende Anleitungen
Wenn du KI-Werkzeuge gerne komplett selbst hostest, passt unsere Anleitung zu Ollama mit Open WebUI in Docker als lokales LLM hervorragend zu diesem Setup - so betreibst du neben der Spracherkennung auch ein eigenes Sprachmodell offline. Wer wissen will, wie leistungsfaehig aktuelle KI-Modelle geworden sind, findet in unserer News zum Release von Anthropic Claude Opus 4.8 einen guten Überblick über den Stand der Technik. Mehr Anleitungen rund um KI sammeln wir in der Kategorie Künstliche Intelligenz.
Quellen
Offizielle Projektseiten und Dokumentation: Purfview/whisper-standalone-win (GitHub), SYSTRAN/faster-whisper (GitHub) und openai/whisper (GitHub).


