LM Studio als lokale KI-Workstation einrichten: Modelle verwalten, testen und per API bereitstellen
LM Studio ist die grafische Alternative zu Ollama für Windows-KMU ohne Docker-Kenntnisse: Modelle aus Hugging Face herunterladen, GGUF-Quantisierungen vergleichen und in 20 Minuten einen lokalen OpenAI-kompatiblen API-Server starten – komplett offline und kostenlos.

Wer lokale Sprachmodelle unter Windows betreiben möchte, ohne sich mit Docker, WSL oder Kommandozeilen-Installationen auseinanderzusetzen, findet in LM Studio eine vollständige grafische Lösung. Die Desktop-Anwendung vereint Modell-Browser, GGUF-Quantisierungsauswahl und einen eingebauten OpenAI-kompatiblen API-Server in einer einzigen Oberfläche – für KMU-Admins ist das der direkteste Weg zu einem lokalen LLM-Endpunkt, der bestehende OpenAI-Integrationen ohne Code-Umbau ersetzt. Diese Anleitung zeigt den vollständigen Weg von der Installation über den Modell-Download bis zum laufenden API-Server, inklusive CLI-Befehlen für den Headless-Betrieb.
Voraussetzungen
- Windows 10 oder Windows 11 (64-Bit) mit AVX2-fähiger CPU (Intel ab ca. 2013, AMD ab Ryzen 1000)
- Mindestens 16 GB RAM – empfohlen sind 32 GB für komfortablen Betrieb mit 7B/8B-Modellen
- Mindestens 4 GB dedizierter VRAM (NVIDIA oder AMD GPU); NVIDIA RTX 50-Serie benötigt Treiber 551.61 oder neuer
- 50–100 GB freier SSD-Speicher für eine kleine Modell-Sammlung
- Internetverbindung für den einmaligen Modell-Download von Hugging Face
- Windows PowerShell 5.1 oder neuer (in Windows 10/11 bereits enthalten)
Schritt 1: LM Studio installieren
Die schnellste Installationsmethode ist der PowerShell-Einzeiler, der den aktuellen Installer herunterlädt und ausführt. Öffne PowerShell als normaler Benutzer (kein Administrator erforderlich) und führe aus:
irm https://lmstudio.ai/install.ps1 | iexAlternativ lädst du den Installer manuell von lmstudio.ai herunter. Nach der Installation findest du LM Studio im Startmenü. Beim ersten Start prüft LM Studio automatisch, ob AVX2 verfügbar ist und welche GPU erkannt wurde.
Verifizieren: Starte LM Studio. In der unteren Statusleiste erscheint die erkannte GPU (z. B. „NVIDIA RTX 4070 – 12 GB VRAM") oder der Hinweis „CPU only". Wenn AVX2 fehlt, zeigt die App eine Fehlermeldung beim Start.
Das CLI-Tool lms wird zusammen mit LM Studio installiert. Damit es in PowerShell verfügbar ist, öffne nach der Installation ein neues Terminal-Fenster:
lms --versionSchritt 2: GGUF-Quantisierung verstehen und Modell wählen
Bevor du ein Modell herunterlädst, lohnt ein Blick auf die Quantisierungsstufen. GGUF ist das Standardformat von llama.cpp und bietet verschiedene Kompressionsstufen, die VRAM-Bedarf gegen Ausgabequalität abwägen. Die folgende Tabelle zeigt die gängigen Stufen am Beispiel eines 7B-Modells:
| Quantisierung | Bits | Größe (7B) | VRAM-Bedarf | Qualität vs. FP16 | Empfehlung |
|---|---|---|---|---|---|
| Q2_K | 2-Bit | ~2,4 GB | unter 6 GB | Deutlich reduziert | Nur bei extremem VRAM-Mangel |
| Q3_K_M | 3-Bit | ~3,2 GB | 4–6 GB | Reduziert | Notlösung für 4-GB-GPUs |
| Q4_K_M | 4-Bit | ~4,4 GB | 6–8 GB | 92–95 % | Standard-Empfehlung |
| Q5_K_M | 5-Bit | ~5,4 GB | 8–12 GB | ~97 % | Sweet Spot für Coding |
| Q6_K | 6-Bit | ~6,4 GB | 12–16 GB | ~99 % | Für 12-GB+-GPUs |
| Q8_0 | 8-Bit | ~8,7 GB | 16–24 GB | Nahezu verlustfrei | Bei großzügigem VRAM |
Für eine typische KMU-Workstation mit 8 GB VRAM ist Q4_K_M die richtige Wahl: Das Modell passt vollständig in den VRAM, und die Qualitätseinbuße gegenüber dem Vollpräzisionsmodell ist im Alltag kaum spürbar. Quantisierung beschleunigt die Inferenz zudem um 10–40 % gegenüber FP16, weil kleinere Gewichte schneller in den VRAM geladen werden. Wer ein 12-GB- oder 16-GB-Modell wie Qwen3-14B betreibt, greift zu Q4_K_M oder Q5_K_M je nach verfügbarem VRAM.
Weitere Details zu GGUF im Vergleich mit AWQ und GPTQ findest du in der Anleitung GGUF, AWQ und GPTQ erklärt.
Schritt 3: Modell über die GUI oder CLI herunterladen
In der LM Studio-Oberfläche öffnest du den Tab „Discover" (Fernglas-Symbol). Suche dort z. B. nach „Qwen3-8B" oder „Llama-3". LM Studio zeigt direkt die verfügbaren GGUF-Varianten mit Dateigröße und Quantisierungsstufe an. Klicke auf die gewünschte Variante und anschließend auf „Download".
Per CLI lässt sich derselbe Schritt automatisieren, etwa für Skripte oder Server-Deployments:
# Modell per CLI herunterladen (Hugging-Face-Bezeichner)
lms get qwen/qwen3-8b-gguf
# Alternativ: nativer REST-API-Aufruf zum Herunterladen
# (wenn der API-Server bereits läuft)
curl -X POST http://localhost:1234/api/v1/models/download `
-H "Content-Type: application/json" `
-d '{"modelId": "bartowski/Qwen3-8B-GGUF"}'Modelle werden unter Windows standardmäßig in %USERPROFILE%\.lmstudio\models gespeichert. Ein 7B Q4_K_M-Modell belegt ca. 4,4 GB auf der Festplatte; für eine kleine Sammlung mehrerer Modelle solltest du 50–100 GB SSD-Speicher einplanen.
Verifizieren: Nach dem Download zeigt lms ls in PowerShell alle lokal vorhandenen Modelle an.
lms lsSchritt 4: Modell laden und API-Server starten
Wähle in LM Studio unter „My Models" das gewünschte Modell aus und klicke auf „Load". In den Lade-Einstellungen kannst du die Kontext-Länge anpassen – achte darauf, dass ein großes Kontextfenster (z. B. 128k Token) erheblich mehr VRAM für den KV-Cache beansprucht. Bei VRAM-Engpässen empfiehlt sich ein Kontextfenster von 4096–8192 Token.
Per CLI lässt sich das Modell direkt mit maximaler GPU-Nutzung laden:
# Modell mit voller GPU-Auslastung laden
lms load qwen3-8b --gpu=max --context-length=8192
# Geladene Modelle anzeigen (liefert den korrekten Bezeichner für API-Aufrufe)
lms psDanach startest du den API-Server. In der GUI wechselst du zum Tab „Developer" und klickst auf „Start Server". Per CLI:
# Lokalen API-Server starten
lms server start
# Status prüfen
lms daemon statusVerifizieren: Der Server läuft, wenn du den folgenden curl-Aufruf absetzt und eine JSON-Liste der geladenen Modelle zurückbekommst:
curl http://localhost:1234/v1/modelsErwartete Ausgabe (gekürzt):
{"object":"list","data":[{"id":"qwen3-8b","object":"model",...}]}Schritt 5: OpenAI-kompatible API nutzen
Der lokale Endpunkt auf Port 1234 repliziert die OpenAI-API vollständig. Du kannst ihn mit curl testen:
curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d "{\"model\": \"qwen3-8b\", \"messages\": [{\"role\": \"user\", \"content\": \"Erklaere GGUF-Quantisierung kurz.\"}], \"temperature\": 0.7}"In bestehenden Python-Projekten, die die openai-Bibliothek nutzen, genügt eine einzige Änderung – die base_url. Kein weiterer Code-Umbau ist nötig:
# pip install openai
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:1234/v1",
api_key="lm-studio" # Wert ist beliebig; lokale Auth ist optional
)
response = client.chat.completions.create(
model="qwen3-8b",
messages=[{"role": "user", "content": "Was ist GGUF?"}],
temperature=0.7
)
print(response.choices[0].message.content)Neben dem OpenAI-kompatiblen Endpunkt (/v1/) bietet LM Studio eine native REST API unter /api/v1/ mit erweitertem Funktionsumfang: Modelle laden und entladen, zustandsbehaftete Chat-Sitzungen, MCP-Integration und Authentifizierung. Diese API eignet sich für Anwendungen, die LM Studio direkt steuern sollen, ohne auf OpenAI-Kompatibilität angewiesen zu sein.
# Natives API: Modell laden
curl -X POST http://localhost:1234/api/v1/models/load \
-H "Content-Type: application/json" \
-d '{"identifier": "qwen3-8b"}'Wer LM Studio in eigene KI-Workflows einbinden möchte, findet in der Anleitung Ollama-Modelle 2026 richtig auswählen ergänzende Hinweise zur VRAM-Planung und Modellauswahl.
Schritt 6: Headless-Betrieb und Autostart einrichten
LM Studio startet den API-Server nicht automatisch beim Windows-Start. Für den dauerhaften Betrieb – etwa als interner KI-Endpunkt im Büronetz – gibt es zwei Optionen:
Option A: Daemon-Modus über die Kommandozeile
# Headless-Daemon starten (kein GUI erforderlich)
lms daemon up
# Daemon-Status prüfen
lms daemon status
# Daemon beenden
lms daemon down
# Logs streamen (für Debugging)
lms log streamOption B: Autostart per Windows-Aufgabenplanung
Erstelle eine neue Aufgabe im Windows-Taskplaner, die beim Systemstart lms daemon up ausführt, gefolgt von lms server start. Als Trigger wählst du „Beim Starten des Computers", als Aktion die PowerShell mit dem Argument -Command "lms daemon up; lms server start". So steht der Endpunkt nach jedem Neustart automatisch zur Verfügung.
Verifizieren: Nach einem Neustart prüfst du mit lms daemon status, ob der Daemon aktiv ist, und rufst http://localhost:1234/v1/models im Browser auf.
LM Studio vs. Ollama: Vergleich für KMU-Admins
LM Studio und Ollama nutzen beide llama.cpp als Inferenz-Engine und erzielen daher nahezu identische Rohgeschwindigkeit. Der entscheidende Unterschied liegt in der Bedienbarkeit und den Einsatzszenarien:
| Kriterium | LM Studio | Ollama |
|---|---|---|
| Benutzeroberfläche | Grafische Desktop-App | CLI-only (kein GUI) |
| Windows-Installation | Installer oder PowerShell-Einzeiler | Installer oder CLI |
| Docker-Support | Nein (nicht für Container ausgelegt) | Ja (offizielles Image) |
| Modell-Browser | Integriert (Hugging Face) | Eigene Bibliothek (100+ Familien) |
| OpenAI-kompatibler Endpunkt | Port 1234 (/v1/) | Port 11434 (/v1/) |
| Headless-Betrieb | lms daemon / llmster | Nativ (Dienst) |
| Einstieg ohne Terminal | Ja, vollständig per GUI | Nein |
| Zielgruppe | Einsteiger, KMU ohne Docker | Entwickler, Server-Deployments |
Für containerisierte Produktions-Deployments in VMs oder Kubernetes ist Ollama die bessere Wahl – LM Studio hat keinen offiziellen Docker-Support. Für den Windows-Desktop-Einsatz und schnelles Experimentieren mit verschiedenen Modellen gewinnt LM Studio durch die grafische Oberfläche und den integrierten Modell-Browser.
Troubleshooting / Typische Fehler
LM Studio startet nicht – „AVX2 not supported"
Ältere CPUs (vor 2013) unterstützen keinen AVX2-Instruktionssatz. Prüfe die CPU-Unterstützung vorab im Task-Manager (Tab „CPU" → „Anweisungssatz") oder mit einem Tool wie CPU-Z. LM Studio lässt sich auf diesen Systemen nicht ausführen.
GPU wird nicht genutzt – nur CPU-Inferenz
Bei NVIDIA RTX 50-Serie erfordert CUDA 12.8 einen Windows-Treiber der Version 551.61 oder neuer. Ist der Treiber zu alt, fällt LM Studio lautlos auf CPU-Inferenz zurück – ohne deutliche Fehlermeldung. Treiber-Version prüfen: nvidia-smi in PowerShell. Aktuelle Treiber gibt es auf der NVIDIA-Webseite.
API-Aufruf schlägt fehl – falscher Modell-Bezeichner
Der model-Parameter im API-Aufruf muss exakt dem LM-Studio-internen Bezeichner entsprechen (z. B. qwen3-8b), nicht dem Hugging-Face-Pfad. Den korrekten Bezeichner liefert lms ps in der Spalte „Identifier".
Langsame Inferenz trotz GPU
Wenn das Modell nicht vollständig in den VRAM passt, lagert LM Studio Teile in den RAM aus (CPU-Offload). Das reduziert die Geschwindigkeit drastisch. Prüfe den VRAM-Bedarf der gewählten Quantisierungsstufe vor dem Download und wähle ggf. eine kleinere Quantisierung (z. B. Q4_K_M statt Q5_K_M).
Großes Kontextfenster verursacht VRAM-Engpass
Ein 128k-Token-Kontext benötigt mehrere GB zusätzlichen VRAM für den KV-Cache. Bei Engpässen das Kontextfenster in den Lade-Einstellungen auf 4096–8192 Token begrenzen.
CORS-Fehler bei Web-App-Integration
Standardmäßig erlaubt der lokale Server nur Anfragen von localhost. Für Web-Apps im Netzwerk musst du die CORS-Einstellungen in LM Studio unter „Developer" → „Server Settings" anpassen und die erlaubten Ursprünge eintragen.
Server startet nach Neustart nicht
Der API-Server startet nicht automatisch. Richte einen Autostart per Windows-Aufgabenplanung ein (siehe Schritt 6) oder starte den Daemon manuell mit lms daemon up && lms server start.
Häufige Fragen
Darf ich LM Studio kostenlos im Unternehmen einsetzen?
Ja. LM Studio 0.4.16 ist explizit kostenlos für privaten und geschäftlichen Gebrauch (Stand Juni 2026). Eine kommerzielle Lizenz ist nicht erforderlich.
Welche GGUF-Quantisierung empfiehlt sich für eine 8-GB-VRAM-GPU?
Q4_K_M ist die Standardempfehlung: Ein 7B-Modell belegt ca. 4,4 GB und lässt ausreichend Puffer für den KV-Cache. Q5_K_M (ca. 5,4 GB) ist möglich, lässt aber weniger Reserve. Q8_0 passt bei 8 GB VRAM nur noch für sehr kleine Modelle unter 3B.
Funktioniert LM Studio ohne GPU, nur mit CPU?
Ja, solange die CPU AVX2 unterstützt. Die Geschwindigkeit ist jedoch deutlich langsamer: Ein 7B Q4_K_M-Modell erreicht auf moderner CPU ca. 8–12 Token/Sekunde, auf einer 8-GB-GPU hingegen 40–80+ Token/Sekunde.
Was ist der Unterschied zwischen dem OpenAI-Endpunkt und der nativen LM-Studio-API?
Der OpenAI-kompatible Endpunkt (/v1/) repliziert die OpenAI-Schnittstelle für Drop-in-Kompatibilität – bestehende Apps funktionieren ohne Code-Änderung. Die native API (/api/v1/) bietet erweiterte Funktionen wie Modell-Management, zustandsbehaftete Sessions und MCP-Integration, ist aber nicht OpenAI-kompatibel.
Wo werden die Modelldateien gespeichert?
Unter Windows standardmäßig in %USERPROFILE%\.lmstudio\models. Der Pfad lässt sich in den LM-Studio-Einstellungen ändern, etwa auf eine externe SSD.
Kann ich den lokalen Endpunkt auch für Continue.dev in VS Code nutzen?
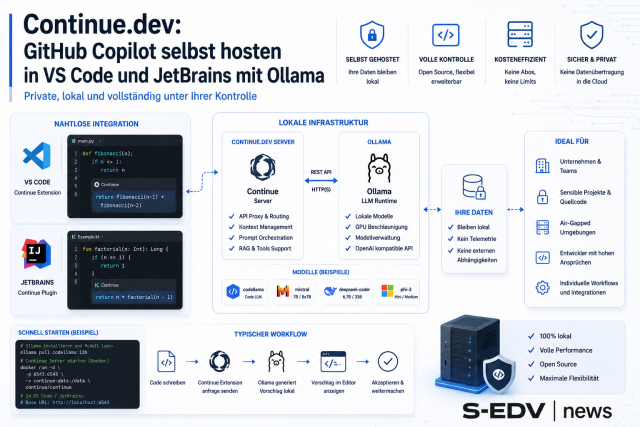
Ja. In der Continue.dev-Konfiguration trägst du als Provider „lmstudio" oder „openai" mit apiBase: "http://localhost:1234/v1" ein. Details dazu in der Anleitung Continue.dev: GitHub Copilot selbst hosten in VS Code mit Ollama.
Fazit
LM Studio ist der unkomplizierteste Weg zu einem lokalen LLM-Endpunkt unter Windows – ohne Docker, ohne WSL, ohne Kommandozeilen-Know-how für den Einstieg. Die Kombination aus integriertem Modell-Browser, übersichtlicher GGUF-Auswahl und sofort einsatzbereitem OpenAI-kompatiblem API-Server macht die Anwendung besonders für KMU-Admins attraktiv, die bestehende OpenAI-Integrationen datenschutzkonform lokal betreiben möchten. Für containerisierte Server-Deployments bleibt Ollama die bessere Wahl – auf dem Windows-Desktop hingegen setzt LM Studio den Maßstab. Mit dem lms-CLI und dem Daemon-Modus lässt sich auch der Headless-Betrieb solide realisieren, sobald die erste Evaluierungsphase abgeschlossen ist.
Weiterführende Anleitungen und Quellen
- Ollama-Modelle 2026 richtig auswählen: VRAM, Quantisierung und Modellvergleich für KMU
- GGUF, AWQ und GPTQ erklärt: Welches Quantisierungsformat für welchen Zweck
- Continue.dev: GitHub Copilot selbst hosten in VS Code und JetBrains mit Ollama
- Ollama und Open WebUI mit Docker: eigenes lokales KI-Sprachmodell ohne Cloud betreiben
- LM Studio offizielle Dokumentation
- LM Studio OpenAI-kompatible API (offiziell)
- LM Studio REST API v1 (offiziell)
- GGUF Quantization Guide 2026: Q4_K_M vs Q8_0 (willitrunai.com)