Hardware-Stresstest unter Linux: CPU, RAM und Disk mit stress-ng und smartctl prüfen
Diese Hardware-Stresstest-Linux-Anleitung zeigt dir Schritt für Schritt, wie du CPU, RAM und Festplatte mit stress-ng, bonnie++ und smartctl validierst, Temperaturen überwachst und defekte Komponenten sauber eingrenzt.
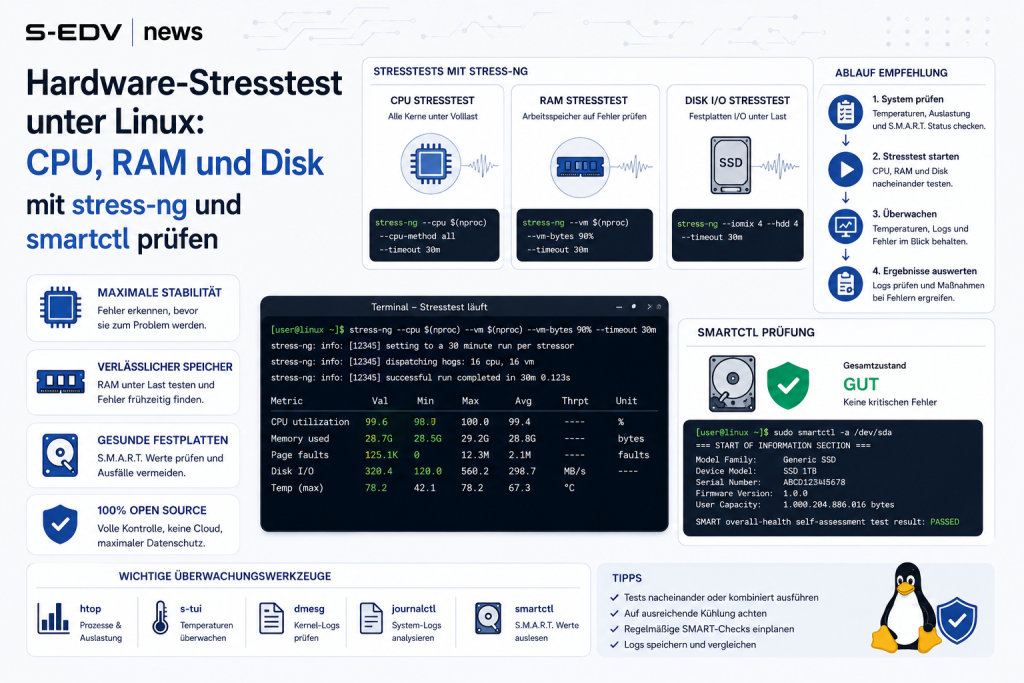
Mit dieser Hardware-Stresstest-Linux-Anleitung validierst du neue oder gebrauchte Hardware systematisch unter Volllast. Egal ob frisch gebauter Homeserver, gebraucht gekaufte CPU oder ein verdächtiges RAM-Modul: Bevor du produktive Dienste oder wichtige Daten auf ein System legst, solltest du CPU, RAM und Festplatte gezielt testen. In dieser Schritt-für-Schritt-Anleitung kombinierst du stress-ng für Last auf CPU, Memory und I/O, bonnie++ für einen Festplatten-Benchmark sowie smartctl aus den smartmontools, um die SMART-Werte deiner Laufwerke auszulesen und Selbsttests zu starten. Zielgruppe sind Admins, Homeserver- und Selfhosting-Nutzer, die Fehler eingrenzen und Systemstabilität testen wollen, statt sie im laufenden Betrieb zu entdecken.
Was ist ein Hardware-Stresstest und warum brauchst du ihn?
Ein Hardware-Stresstest belastet einzelne Komponenten deutlich stärker als der Alltagsbetrieb, um Schwachstellen sichtbar zu machen, die unter normaler Last verborgen bleiben. Defekte RAM-Riegel, instabile Übertaktungen, zu hohe Temperaturen durch schlecht sitzende Kühler oder Festplatten mit wachsenden Fehlersektoren zeigen sich oft erst, wenn das System minutenlang am Limit läuft.
stress-ng ist der De-facto-Standard unter Linux, um synthetische Last auf CPU, Speicher und I/O zu erzeugen. memtester prüft den Arbeitsspeicher gezielt auf Bitfehler, bonnie++ liefert reproduzierbare Durchsatz- und IOPS-Werte für Laufwerke, und smartctl aus den smartmontools liest die SMART-Selbstdiagnose moderner SSDs und HDDs aus. Zusammen ergibt das ein vollständiges Bild der Hardwaregesundheit. Die Grundregel: Ein Crash unter Last deutet fast immer auf Überhitzung oder eine instabile Spannungsversorgung hin, während ein reproduzierbarer Fehler (etwa ein Bitfehler im RAM oder ein wachsender Pending-Sector-Count) auf einen echten Hardwaredefekt hinweist.
Voraussetzungen
- Ein Linux-System (Debian/Ubuntu, Fedora oder Arch) mit
root- bzw.sudo-Rechten. - Ein Terminalzugang, idealerweise zwei Sitzungen (eine für die Last, eine fürs Monitoring) oder ein Terminal-Multiplexer wie
tmux. - Ausreichend Kühlung und eine stabile Stromversorgung; bei Notebooks am Netzteil testen.
- Wichtig: Ein aktuelles Backup, falls du Schreibtests (bonnie++) ausführst. Disk-Benchmarks erzeugen reale Schreiblast.
- Für SMART-Tests SATA-, SAS- oder NVMe-Laufwerke, die SMART unterstützen (heute praktisch alle).
- Etwas Zeit: 30-60 Minuten für einen normalen Durchlauf, 8 Stunden oder mehr für kritische Fälle.
Schritt 1: Tools installieren
Installiere die benötigten Pakete für deine Distribution. lm-sensors liefert die Temperatur- und Spannungswerte fürs Monitoring.
# Debian / Ubuntu
sudo apt update
sudo apt install -y stress-ng memtester bonnie++ smartmontools lm-sensors
# Fedora
sudo dnf install -y stress-ng memtester bonnie++ smartmontools lm_sensors
# Arch Linux
sudo pacman -S --needed stress-ng memtester bonnie++ smartmontools lm_sensorsInitialisiere danach die Sensoren einmalig. Bestätige die Erkennung mit Enter und übernimm die Vorschläge:
sudo sensors-detect --auto
sensorsSchritt 2: System-Baseline und CPU-Topologie ermitteln
Bevor du Last erzeugst, solltest du die Ausgangswerte kennen: Anzahl der Kerne, RAM-Größe und die Ruhetemperaturen. So erkennst du später, ob unter Last etwas aus dem Ruder läuft.
# CPU-Kerne und Modell
lscpu | grep -E 'Model name|^CPU\(s\)|Thread'
# Verfügbarer Arbeitsspeicher
free -h
# Ruhetemperaturen ablesen
sensorsNotiere dir die Anzahl der logischen Kerne (Wert CPU(s)) und den freien Arbeitsspeicher. Diese Werte brauchst du, um die Last sinnvoll zu dimensionieren.
Schritt 3: Monitoring in einer zweiten Sitzung starten
Öffne ein zweites Terminal oder ein zweites tmux-Pane. Hier beobachtest du die Temperaturen im Sekundentakt, während im ersten Terminal die Last läuft. Dieser Schritt ist entscheidend, denn ein Stresstest ohne Temperaturüberwachung verrät dir nicht, warum ein System abstürzt.
# Temperaturen jede Sekunde aktualisieren
watch -n 1 sensors
# Alternativ kombiniert mit Taktraten
watch -n 1 "sensors; echo; grep 'MHz' /proc/cpuinfo | head -n 8"Als Faustregel gilt: Moderne Desktop-CPUs sollten unter Dauerlast deutlich unter ihrer Throttling-Grenze bleiben (meist 90-100 Grad Celsius). Erreicht die CPU diese Grenze und taktet herunter, ist die Kühlung unterdimensioniert oder die Wärmeleitpaste schlecht aufgetragen.
Schritt 4: CPU, RAM und I/O kombiniert stressen mit stress-ng
Jetzt kommt der Kern dieser Anleitung. Der folgende Befehl belastet vier CPU-Kerne, startet zwei Speicher-Stressoren und zwei I/O-Worker. Passe die Zahlen an deine Hardware an: --cpu entspricht idealerweise der Anzahl deiner logischen Kerne aus Schritt 2.
# Kombinierter Stresstest über 60 Minuten
stress-ng --cpu 4 --vm 2 --io 2 --timeout 60m --metrics-brief
# Alle Kerne automatisch belegen (0 = alle CPUs)
stress-ng --cpu 0 --vm 1 --vm-bytes 80% --io 2 --timeout 60m --metrics-briefDie wichtigsten Optionen im Überblick:
--cpu Nstartet N Worker, die die CPU mit Rechenoperationen auslasten.--vm Nstartet N Speicher-Worker;--vm-byteslegt fest, wie viel RAM jeder einzelne Worker allokiert. Achtung: Der Prozentwert gilt pro Worker, daher würden zwei Worker mit80%zusammen 160 % belegen und ins Swap oder in den OOM-Killer laufen. Nutze deshalb entweder--vm 1 --vm-bytes 80%oder mehrere Worker mit kleinerem Anteil (z. B.--vm 2 --vm-bytes 40%).--io Nerzeugt N Worker, die persync()I/O-Last erzeugen.--timeout 60mbeendet den Test nach 60 Minuten; auch30m,8husw. sind möglich.--metrics-briefgibt am Ende eine kompakte Zusammenfassung der durchgeführten Operationen aus.
Für einen reinen CPU-Hitzetest mit maximaler Wärmeentwicklung eignet sich die matrixprod-Methode besonders gut:
stress-ng --cpu 0 --cpu-method matrixprod --timeout 30m --metrics-briefBeobachte währenddessen das Monitoring-Terminal. Stürzt das System ab oder friert es ein, ist das ein starkes Indiz für Überhitzung oder eine instabile Spannungsversorgung. Bricht stress-ng mit einer Fehlermeldung ab, prüfe die Ausgabe genau.
Schritt 5: RAM gezielt auf Fehler testen
Die --vm-Last von stress-ng belastet den Speicher, ist aber kein dedizierter Fehlertest. Für RAM-Fehler unter Linux nutzt du memtester, das den Speicher mit bekannten Mustern beschreibt und zurückliest. Reserviere weniger RAM, als physisch verbaut ist, damit der Test nicht ins Swap läuft.
# 4096 MB Arbeitsspeicher in 1 Durchlauf prüfen
sudo memtester 4096M 1
# Mehrere Durchläufe für höhere Aussagekraft
sudo memtester 4096M 5Jede Zeile sollte mit ok abschließen. Tauchen FAILURE-Meldungen auf, hast du mit hoher Wahrscheinlichkeit einen defekten RAM-Riegel oder ein Speicher-Timing-Problem. Für einen vollständigen Test des gesamten Speichers (inklusive des vom Kernel belegten Bereichs) ist ein Offline-Test mit Memtest86+ aus dem Bootmenü die gründlichere, aber zeitaufwendigere Variante.
Schritt 6: SMART-Werte auslesen und Selbsttest starten mit smartctl
Bevor du die Festplatte mit Last belastest, lies ihre SMART-Selbstdiagnose aus. Ermittle zuerst das richtige Gerät und prüfe dann die Gesamtgesundheit.
# Verfügbare Laufwerke anzeigen
lsblk -d -o NAME,SIZE,MODEL
# Schnelle Gesundheitsbewertung
sudo smartctl -H /dev/sda
# Vollständige SMART-Attribute und Fehlerprotokoll
sudo smartctl -a /dev/sdaAchte besonders auf die Attribute Reallocated_Sector_Ct, Current_Pending_Sector und Offline_Uncorrectable. Werte über null oder steigende Werte sind Warnsignale. Starte anschließend den ausführlichen SMART-Selbsttest, der die gesamte Oberfläche prüft:
# Langen Selbsttest starten (läuft im Hintergrund des Laufwerks)
sudo smartctl -t long /dev/sda
# Geschätzte Laufzeit und Fortschritt abfragen
sudo smartctl -a /dev/sda | grep -A2 "Self-test execution"
# Nach Abschluss das Testprotokoll prüfen
sudo smartctl -l selftest /dev/sdaDer lange Test kann je nach Laufwerksgröße mehrere Stunden dauern und läuft auf dem Laufwerk selbst, du kannst das Terminal also schließen. Das Ergebnis sollte Completed without error lauten. Für NVMe-Laufwerke verwendest du dieselben Befehle mit dem Gerätenamen /dev/nvme0.
Schritt 7: Festplatten-Benchmark mit bonnie++
Für einen reproduzierbaren Durchsatz- und IOPS-Test nutzt du bonnie++. Lege das Testverzeichnis auf das zu prüfende Laufwerk und gib eine Dateigröße an, die den RAM-Cache übersteigt (Faustregel: das Doppelte des verbauten RAM), damit du echten Plattendurchsatz misst und nicht den Cache.
# Testverzeichnis auf dem Ziellaufwerk anlegen
sudo mkdir -p /mnt/data/bonnie_test
sudo chown "$USER" /mnt/data/bonnie_test
# Benchmark mit 16 GB Testdaten ausführen
bonnie++ -d /mnt/data/bonnie_test -s 16G -n 0 -u "$USER"Die Option -s 16G legt die Größe der Testdatei fest, -n 0 überspringt den separaten Test mit vielen kleinen Dateien (für reine Durchsatzmessung), und -u gibt den Benutzer an, da bonnie++ nicht als root laufen will. Die Ausgabe zeigt sequenzielle Schreib- und Leseraten sowie Random-Seeks. Vergleiche die Werte mit den Herstellerangaben deines Laufwerks: Liegen sie deutlich darunter, prüfe Kabel, SATA-Port oder den Zustand der SSD.
Schritt 8: Verifikation und Auswertung
Nach den Tests fasst du die Ergebnisse zusammen. Ein System gilt als validiert, wenn alle folgenden Punkte zutreffen:
- Der
stress-ng-Lauf lief über die gesamte Dauer ohne Absturz oder Einfrieren durch. - Die CPU-Temperatur blieb unter der Throttling-Grenze und es gab kein dauerhaftes Heruntertakten.
memtestermeldete für jeden DurchlaufokohneFAILURE.smartctl -l selftestzeigtCompleted without errorund die kritischen SMART-Attribute stehen auf null.bonnie++lieferte plausible Durchsatzwerte im Bereich der Herstellerangaben.
Prüfe abschließend das Kernel-Log auf Hardware-Fehler, die während der Tests aufgetreten sein könnten, etwa Machine-Check-Exceptions (MCE) oder I/O-Errors:
sudo dmesg --level=err,warn | grep -iE "mce|hardware error|i/o error|ata"
journalctl -k -p err --no-pagerUpdates und Wartung
Halte die smartmontools aktuell, damit die Laufwerks-Datenbank neue Modelle korrekt erkennt. Aktualisiere die Datenbank und die Pakete regelmäßig:
# Pakete aktualisieren (Debian/Ubuntu)
sudo apt update && sudo apt upgrade -y stress-ng smartmontools
# SMART-Laufwerksdatenbank aktualisieren
sudo update-smart-drivedbFür den Dauerbetrieb empfiehlt sich der smartd-Dienst, der SMART-Werte automatisch überwacht und dich per Mail warnt, sobald Attribute kritisch werden. Aktiviere ihn nach Bedarf und konfiguriere /etc/smartd.conf. So musst du nicht manuell prüfen, sondern wirst proaktiv informiert. Plane außerdem regelmäßige kurze SMART-Selbsttests (smartctl -t short) ein, etwa wöchentlich per Cronjob.
Backup-Hinweis: Ein bestandener Stresstest ersetzt kein Backup. Gerade bei gebrauchter Hardware oder Laufwerken mit auffälligen SMART-Werten solltest du eine durchdachte Backup-Strategie fahren. Wie du Datenträger vor dem Wiederverkauf rückstandslos leerst, zeigt unsere Anleitung zum sicheren Löschen von Festplatten.
Troubleshooting
- System friert unter stress-ng ein oder startet neu: Klassisches Zeichen für Überhitzung oder zu hohe/instabile Spannung. Prüfe die Temperaturen im Monitoring, reinige den Kühler, erneuere die Wärmeleitpaste und deaktiviere etwaige Übertaktungen oder XMP/EXPO-Profile im BIOS.
- memtester meldet FAILURE: Teste die Riegel einzeln, um den defekten zu identifizieren. Tausche Steckplätze, um einen Slot-Defekt auszuschließen. Setzt sich der Fehler fort, ist der Riegel defekt.
- smartctl meldet "Device does not support SMART" oder liefert nichts: Bei USB-Gehäusen oder RAID-Controllern hilft oft die Angabe des Gerätetyps, z. B.
sudo smartctl -d sat -a /dev/sdaoder-d nvmebzw.-d cciss,0. - bonnie++ verweigert den Start als root: Lege die Tests als normaler Benutzer an oder nutze die Option
-umit einem Nicht-Root-Benutzer. - sensors zeigt keine Temperaturen: Führe
sudo sensors-detecterneut aus, lade die vorgeschlagenen Kernelmodule und prüfe, ob das Mainboard vonlm-sensorsunterstützt wird. - Current_Pending_Sector steigt: Sichere sofort deine Daten. Wachsende Pending-Sektoren sind ein deutliches Anzeichen für ein sterbendes Laufwerk.
Häufige Fragen
Wie lange sollte ein Hardware-Stresstest unter Linux laufen?
Für einen normalen Funktionstest reichen 30 bis 60 Minuten unter Volllast. Wenn du seltene Fehler oder thermische Probleme im Dauerbetrieb eingrenzen willst, etwa bei gebrauchter Server-Hardware, solltest du 8 Stunden oder länger testen, da sich manche Defekte erst nach längerer Wärmeentwicklung zeigen.
Was bedeutet ein Crash während des stress-ng-Tests?
Ein Absturz oder Einfrieren unter Last deutet fast immer auf Überhitzung oder eine instabile Spannungsversorgung hin, nicht zwingend auf einen defekten Chip. Prüfe zuerst die Temperaturen und die Stromversorgung, deaktiviere Übertaktungen und teste erneut. Treten dagegen reproduzierbare Datenfehler auf, liegt ein echter Hardwaredefekt vor.
Reicht stress-ng allein, um RAM-Fehler zu finden?
Die --vm-Stressoren von stress-ng belasten den Speicher, ersetzen aber keinen dedizierten Speicher-Fehlertest. Für zuverlässige Ergebnisse nutzt du zusätzlich memtester im laufenden System oder Memtest86+ vom Bootmedium, das auch den vom Kernel belegten Speicherbereich prüft.
Schadet ein Stresstest meiner Hardware?
Bei funktionierender Kühlung und Standard-Einstellungen ist ein zeitlich begrenzter Stresstest unbedenklich, denn die Komponenten sind für Volllast ausgelegt. Sorge für ausreichende Kühlung, teste Notebooks am Netzteil und beobachte die Temperaturen. Bonnie++ erzeugt echte Schreiblast, daher gehört dorthin ein gültiges Backup.
Worin unterscheiden sich smartctl -t short und -t long?
Der kurze Selbsttest (-t short) dauert wenige Minuten und prüft elektrische und mechanische Grundfunktionen. Der lange Test (-t long) scannt die gesamte Laufwerksoberfläche und kann mehrere Stunden in Anspruch nehmen, ist dafür aber deutlich gründlicher beim Aufspüren von Lesefehlern.
Fazit
Mit dieser Hardware-Stresstest-Linux-Anleitung hast du eine reproduzierbare Routine, um CPU, RAM und Festplatte systematisch zu validieren. stress-ng deckt instabile Systeme und Kühlungsprobleme auf, memtester findet Speicherfehler, bonnie++ misst den realen Festplattendurchsatz und smartctl liefert die SMART-Diagnose deiner Laufwerke. Kombiniert mit konsequentem Temperatur-Monitoring per watch -n 1 sensors grenzt du Defekte zuverlässig ein, bevor sie im Produktivbetrieb teuer werden. Plane 30 bis 60 Minuten für den Standardfall und mehrere Stunden für kritische Hardware ein.
Weiterführende Anleitungen und Quellen
Wenn du Hardware für anspruchsvolle Workloads validierst, lohnt auch ein Blick auf aktuelle Enterprise-Beschleuniger wie die AMD Instinct MI350P PCIe-AI-GPU für den Enterprise-Einsatz. Für die sichere Außerbetriebnahme geprüfter Datenträger findest du in unserer Anleitung zum sicheren Löschen von Festplatten alle Schritte. Weitere praxisnahe Tutorials sammeln wir in der Kategorie Hardware.
Quellen: Offizielle Projektdokumentation von stress-ng, smartmontools und bonnie++.